We want to identify biodiversity refuge zones in Madagascar.
2 Datasets
2.1 Forest inventory
National forest inventories carried out on \(753\) sites on the island of Madagascar are available, listing the presence or absence of \(555\) plant species on each of these sites between 1994 and 1996. We use these forest inventories to calculate a matrix indicating the presence by a \(1\) and the absence by a \(0\) of the species at each site by removing observations for which the species is not identified. This matrix therefore records the occurrences of \(483\) species at \(751\) sites.
# forest inventory
trees <- read.csv("~/Documents/projet_BioSceneMada/forest_inventory_Madagascar.csv")
trees <- trees[-which(is.na(trees$sp)),]
trees$plot <- as.character(trees$plot)
plots <- unique(trees$plot)
nplot <- length(plots)
sp <- unique(trees$taxize)
nsp <- length(sp)
# presence/absence of each species on each plot
nplot <- length(unique(trees$plot))
species <- unique(trees$taxize)
nsp <- length(species)
# presence/absence of each species on each plot
PA <- matrix(0, nplot, nsp)
rownames(PA) <- paste(sort(as.numeric(unique(trees$plot))))
colnames(PA) <- paste0("sp_", 1:nsp)
for (i in 1:nplot){
for (j in 1:nsp){
idx <- which(trees$taxize == species[j])
PA[paste(trees$plot[idx]),j] <- 1
}
}
madagascar <- PA
# save presence/absence at inventory sites matrix
save(madagascar, file="~/Documents/jSDM/data/madagascar.rda")We represent the presence-absence matrix obtained for the twenty first species.
oldwd <- getwd()
data(madagascar, package="jSDM")
head(madagascar[,1:20])
#> sp_1 sp_2 sp_3 sp_4 sp_5 sp_6 sp_7 sp_8 sp_9 sp_10 sp_11 sp_12 sp_13 sp_14
#> 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
#> 2 0 0 0 0 0 1 0 0 0 0 0 0 0 0
#> 3 0 0 0 0 0 0 0 0 1 0 0 0 0 0
#> 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0
#> 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0
#> 6 0 0 0 1 0 0 0 0 0 0 0 0 0 1
#> sp_15 sp_16 sp_17 sp_18 sp_19 sp_20
#> 1 0 0 0 0 0 0
#> 2 0 0 0 0 0 0
#> 3 0 0 0 0 0 0
#> 4 0 0 0 0 0 0
#> 5 0 0 0 0 0 0
#> 6 0 0 0 0 0 02.2 Current environmental variables
We use the function get_chelsa_current from the R package gecevar to download a set of climatic data for Madagascar Island from the website: .
2.2.1 Downloading
# devtools::install_github("ghislainv/gecevar")
library(gecevar)
name <- "Madagascar"
epsg <- 32738
output_file <- "/home/clement/Documents/projet_BioSceneMada/Internship_Report/data"
setwd("/home/clement/Documents/jSDM/vignettes/Madagascar_files/")
# Get Madagascar extent in the specified coordinates system (EPSG)
output <- transform_shp_country_extent(EPSG = epsg,
country_name = name,
rm_download=FALSE)
save(output, file="~/Documents/projet_BioSceneMada/Internship_Report/data/output.RData")
extent <- output[[1]][1]
extent_latlon <- as.numeric(output[[1]][2:5])
clim_path <- get_chelsa_current(extent_latlon = extent_latlon,
extent = extent,
EPSG = epsg,
destination = output_file,
resolution = 1000,
rm_download = TRUE)| Variable | Unit |
|---|---|
| Minimum monthly temperatures | °C x 10 |
| Maximum monthly temperatures | °C x 10 |
| Average monthly temperatures | °C x 10 |
| Monthly precipitation | \(kg.m^{-2}.month^-1\) |
| Cloud cover | % |
| Climatic water deficit (Thornthwaite) | \(kg.m^{-2}\) |
| Potential evapotranspiration (Thornthwaite) | \(kg.m^{-2}.month^-1\) |
| Number of dry months (Thornthwaite) | months |
| Climatic water deficit (Penman-Monteith) | \(kg.m^{-2}\) |
| Potential evapotranspiration (Penman-Monteith) | \(kg.m^{-2}.month^-1\) |
| Number of dry months (Penman-Monteith) | months |
| Annual mean temperature (bio1 or temp) | °C x 10 |
| Diurnal temperature range (bio2) | °C x 10 |
| Isothermality (bio3=bio2/bio7) | °C x 10 |
| Seasonality of temperatures (bio4 or sais_temp) | °C x 10 |
| Maximum temperature of the warmest month (bio5) | °C x 10 |
| Minimum temperature of the coldest month (bio6) | °C x 10 |
| Annual temperature range (bio7=bio5-bio6) | °C x 10 |
| Average temperature of the wettest quarter (bio8) | °C x 10 |
| Average temperature of the driest quarter (bio9) | °C x 10 |
| Average temperature of the warmest quarter (bio10) | °C x 10 |
| Average temperature of the coldest quarter (bio11) | °C x 10 |
| Cumulative annual precipitation (bio12 or prec) | \(kg.m^{-2}.year^{-1}\) |
| Cumulative precipitation of wettest month (bio13) | \(kg.m^{-2}.month^{-1}\) |
| Cumulative precipitation of the driest month (bio14) | \(kg.m^{-2}.month^{-1}\) |
| Seasonality of rainfall (bio15 or sais_prec) | \(kg.m^{-2}\) |
| Precipitation in wettest quarter (bio16) | \(kg.m^{-2}.month^{-1}\) |
| Precipitation of driest quarter (bio17) | \(kg.m^{-2}.month^{-1}\) |
| Warmest quarter precipitation (bio18) | \(kg.m^{-2}.month^{-1}\) |
| Coldest quarter precipitation (bio19) | \(kg.m^{-2}.month^{-1}\) |
2.2.2 Desing matrix
Among the climatic data downloaded, concerning the whole island of Madagascar at present (interpolations of representative observed data from the years 1960-1990). We choose to use the following variables because they have an ecological meaning which makes them easily interpretable and are little correlated between them according to the article Vieilledent et al. (2013) :
- temp: the average annual temperature (\(^\circ C\times 10\)).
- prec: the average annual precipitation (mm).
- sais_temp: the seasonality of temperatures corresponds to the standard deviation of monthly temperatures multiplied by \(100\).
- sais_prec: the seasonality of precipitation as a coefficient of variation.
- cwd: the annual climatic water deficit (mm) is based on monthly precipitation (\(prec\)) and potential evapotranspiration (\(pet\)) which is defined as the amount of evaporation that would occur in a month if a sufficient water source were available: \(\mathrm{cwd}= \sum_{m=1}^{12}\min(0, \ \mathrm{prec}_m-\ \mathrm{pet}_m)\).
We consider also the quadratic effects of these climate variables to perform a quadratic regression, which is more suitable for fitting a niche model than a linear regression.
load(file="~/Documents/projet_BioSceneMada/Internship_Report/data/output.RData")
clim_path <- "/home/clement/Documents/projet_BioSceneMada/Internship_Report/data/data_raw/current_chelsa.tif"
# get interesting covariates among the climatic variables downloaded
clim_var <- terra::rast(clim_path,
lyrs=c("bio1", "bio4", "bio12", "bio15", "cwd_penman"))
names(clim_var) <- c("temp", "sais_temp", "prec", "sais_prec", "cwd")
proj <- terra::crs(clim_var)
# Data restricted to Madagascar's borders
borders <- terra::vect(output[[2]], layer="gadm36_MDG_0")
borders <- terra::project(borders, proj)
clim_var_mada <- terra::mask(clim_var, borders)
# representation
par(oma=c(0,0,2,1))
terra::plot(clim_var_mada, legend=TRUE)
title("Current bioclimatic variables", outer=TRUE, cex=0.8)
# spatial points of each plot
coords <- unique(cbind(trees$long,trees$lat, as.numeric(trees$plot)))
coords <- coords[sort(coords[,3], index.return=TRUE)$ix,]
longlat <- terra::vect(coords[,1:2], crs="+proj=longlat +ellps=clrk66")
# lat long to UTM38S projection
xy <- terra::project(longlat, proj)
terra::writeVector(xy, overwrite=TRUE,
"/home/clement/Documents/projet_BioSceneMada/Internship_Report/data/coords.shp")
# Add squared data
clim_var2 <- c(clim_var_mada, clim_var_mada^2)
names(clim_var2) <- c(names(clim_var), paste0(names(clim_var),
rep("2", dim(clim_var)[3])))
# extract climatic data on each plot
clim2 <- terra::extract(clim_var2,xy)
pos <- coords
colnames(pos) <- c("long","lat","site")
# Add squared data
data_clim2 <- data.frame(cbind(clim2[,-1],pos))
nparam <- ncol(data_clim2) -3
library(tidyverse)
# reduced centered data
scaled_data_clim2 <- scale(data_clim2[,1:nparam])
means <- attr(scaled_data_clim2,"scaled:center")
sds <- attr(scaled_data_clim2,"scaled:scale")
scaled_data_clim2 <- as_tibble(cbind(site=data_clim2$site,
scaled_data_clim2,
lat=data_clim2$lat,
long=data_clim2$long))
## Design matrix
X <- data.frame(intercept=rep(1, nrow(pos)),
dplyr::select(scaled_data_clim2,-lat,-long, -site))
np <- ncol(X)
write.csv(X, file = "~/Documents/projet_BioSceneMada/Internship_Report/data/X.csv",
row.names = F)
# save climatic data at inventory sites
save(scaled_data_clim2, means, sds,
file="~/Documents/projet_BioSceneMada/Internship_Report/data/scaled_data_clim.RData")
# save raster in .tif format
# Center and reduce climatic variables
# using means and standard deviations of climatic variables at inventory sites
scaled_clim_var <- (clim_var2-means)/sds
names(scaled_clim_var) <- names(clim_var2)
terra::writeRaster(scaled_clim_var,
"~/Documents/projet_BioSceneMada/Internship_Report/data/scaled_clim.tif",
gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)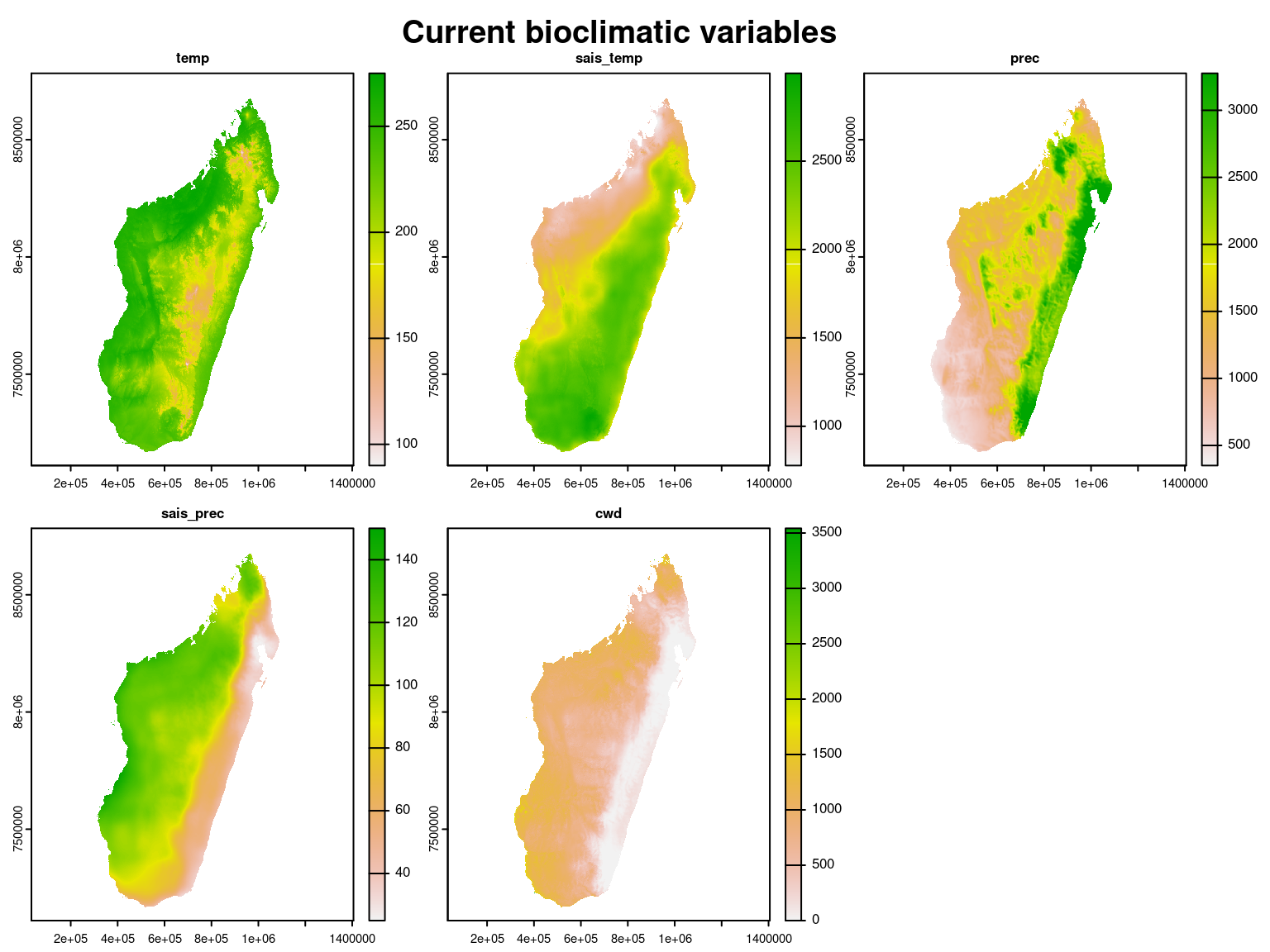
The values of these climate variables corresponding to the coordinates of the inventory plots are extracted and scaled to obtain the following data-set where coordinates of the sites will then be used for spatial interpolation and to spatially represent the results.

3 Fitting joint species distribution model (JSDM)
3.1 Model definition
Referring to the models used in the articles Warton et al. (2015) and Albert & Siddhartha (1993), we define the following latent variable model (LVM) to account for species co-occurrence on all sites :
\[ \mathrm{probit}(\theta_{ij}) =\alpha_i + \beta_{0j}+X_i.\beta_j+ W_i.\lambda_j \]
Link function probit: \(\mathrm{probit}: q \rightarrow \Phi^{-1}(q)\) where \(\Phi\) correspond to the distribution function of the reduced centered normal distribution.
Response variable: \(Y=(y_{ij})^{i=1,\ldots, n_{site}}_{j=1,\ldots,n_{species}}\) with:
\[y_{ij}=\begin{cases} 0 & \text{ if species $j$ is absent on the site $i$}\\ 1 & \text{ if species $j$ is present on the site $i$}. \end{cases}\]
- Latent variable \(z_{ij} = \alpha_i + \beta_{0j} + X_i.\beta_j + W_i.\lambda_j + \epsilon_{i,j}\), with \(\forall (i,j) \ \epsilon_{ij} \sim \mathcal{N}(0,1)\) and such that:
\[y_{ij}=\begin{cases} 1 & \text{if} \ z_{ij} > 0 \\ 0 & \text{otherwise.} \end{cases}\]
It can be easily shown that: \(y_{ij} \sim \mathcal{B}ernoulli(\theta_{ij})\).
Latent variables: \(W_i=(W_i^1,\ldots,W_i^q)\) where \(q\) is the number of latent variables considered, which has to be fixed by the user (by default \(q=2\)). We assume that \(W_i \sim \mathcal{N}(0,I_q)\) and we define the associated coefficients \(\lambda_j=(\lambda_j^1,\ldots, \lambda_j^q)'\), also known as “factor loadings” (Warton et al. 2015). We use a prior distribution \(\mathcal{N}(0,1)\) for all lambda not concerned by constraints to \(0\) on upper diagonal and to strictly positive values on diagonal.
Explanatory variables: bio-climatic data about each site. \(X=(X_i)_{i=1,\ldots,n_{site}}\) with \(X_i=(x_i^1,\ldots,x_i^p)\in \mathbb{R}^p\) where \(p\) is the number of bio-climatic variables considered. The corresponding regression coefficients for each species \(j\) are noted : \(\beta_j=(\beta_j^1,\ldots,\beta_j^p)'\). We use a prior distribution \(\mathcal{N}(0,1)\) for all beta.
\(\beta_{0j}\) correspond to the intercept for species \(j\) which is assumed to be a fixed effect. We use a prior distribution \(\mathcal{N}(0,10)\) for the species intercept.
\(\alpha_i\) represents the random effect of site \(i\) such as \(\alpha_i \sim \mathcal{N}(0,V_{\alpha})\) and we assume that \(V_{\alpha} \sim \mathcal {IG}(\text{shape}=0.1, \text{rate}=0.1)\) as prior distribution by default.
This model is equivalent to a multivariate GLMM \(\mathrm{g}(\theta_{ij}) = \alpha_i + X_i.\beta_j + u_{ij}\), where \(u_{ij} \sim \mathcal{N}(0, \Sigma)\) with the constraint that the variance-covariance matrix \(\Sigma = \Lambda \Lambda^{\prime}\), where \(\Lambda\) is the full matrix of factor loadings, with the \(\lambda_j\) as its columns.
3.2 Parameters inference
We fit a binomial joint species distribution model, including two latent variables and random site effect using the jSDM_binomial_probit() function to perform binomial probit regression considering all the species from the data described above, by performing \(80 000\) iterations including \(40 000\) of burn-in and we retain \(N_{samp}=1 000\) values for each parameter of the model.
We use species’s prevalence as starting values for species intercept \(\beta_0\).
load("~/Documents/projet_BioSceneMada/Internship_Report/data/scaled_data_clim.RData")
data(madagascar, package="jSDM")
PA <- madagascar
# Prevalence of species
np <- ncol(dplyr::select(scaled_data_clim2, -site, -lat, -long)) +1
prevalence <- colSums(PA)/nrow(PA)
beta_start <- matrix(0,np,ncol(PA))
beta_start[1,] <- qnorm(prevalence)
#
T1<- Sys.time()
mod_all <- jSDM::jSDM_binomial_probit(
# Response variable
presence_data = PA,
# Explanatory variables
site_formula = ~ temp + prec + sais_temp + sais_prec + cwd + temp2 + prec2 + sais_temp2 + sais_prec2 + cwd2,
site_data=scaled_data_clim2,
n_latent=2,
site_effect="random",
# Chains
burnin= 40000, mcmc=40000, thin=40,
# Starting values
alpha_start=0, beta_start=beta_start,
lambda_start=0, W_start=0,
V_alpha=1,
# Priors
shape_Valpha=0.1,
rate_Valpha=0.1,
mu_beta=0, V_beta=c(10,rep(1,np-1)),
mu_lambda=0, V_lambda=1,
# Various
seed=1234, verbose=1)
T2 <- Sys.time()
T_all <- difftime(T2,T1)
save(mod_all,T_all,file="~/Documents/projet_BioSceneMada/Internship_Report/data/mada_mod.RData")
The MCMC algorithm is used to obtain draws from the posterior distribution of the parameters. We use as estimator for each parameter the mean of the \(N_{samp}\) values estimated in corresponding MCMC chain and we save the estimated parameters in .csv format.
load("~/Documents/projet_BioSceneMada/Internship_Report/data/mada_mod.RData")
load("~/Documents/projet_BioSceneMada/Internship_Report/data/scaled_data_clim.RData")
species <- colnames(mod_all$model_spec$presence_data)
nplot <- nrow(mod_all$model_spec$presence_data)
nsp <- ncol(mod_all$model_spec$presence_data)
n_latent <- mod_all$model_spec$n_latent
np <- nrow(mod_all$model_spec$beta_start)
## Save parameters
### alphas
alphas <- apply(mod_all$mcmc.alpha,2,mean)
### V_alpha
V_alpha <- mean(mod_all$mcmc.V_alpha)
### latent variables
W1 <- colMeans(mod_all$mcmc.latent[["lv_1"]])
W2 <- colMeans(mod_all$mcmc.latent[["lv_2"]])
params_sites <- data.frame(plot = scaled_data_clim2$site,
lat = scaled_data_clim2$lat,
long = scaled_data_clim2$long,
alphas, V_alpha = rep(V_alpha,nplot),W1,W2)
write.csv(params_sites, file = "~/Documents/projet_BioSceneMada/Internship_Report/data/params_sites.csv",row.names = F)
### fixed species effect lambdas and betas
lambdas <- matrix(0,nsp,n_latent)
betas <- matrix(0,nsp,np)
for (j in 1:nsp){
for (l in 1:n_latent){
lambdas[j,l] <- mean(mod_all$mcmc.sp[[j]][,np+l])
}
for (p in 1:np){
betas[j,p] <- mean(mod_all$mcmc.sp[[j]][,p])
}
}
colnames(betas) <- colnames(mod_all$mcmc.sp[[1]])[1:np]
params_species <- data.frame(species=species, Id_species = c(1:nsp),
betas, lambda_1 = lambdas[,1], lambda_2 = lambdas[,2])
write.csv(params_species,
file ="~/Documents/projet_BioSceneMada/Internship_Report/data/params_species.csv",
row.names = F)
## probit_theta_latent
write.csv(mod_all$probit_theta_latent,
file = "~/Documents/projet_BioSceneMada/Internship_Report/data/probit_theta_latent.csv",
row.names = F)
## theta_latent
write.csv(mod_all$theta_latent, file = "~/Documents/projet_BioSceneMada/Internship_Report/data/theta_latent.csv", row.names = F)3.3 Evaluation of MCMC convergence
We visually evaluate the convergence of MCMCs by representing the trace and density a posteriori of the estimated parameters.
load("~/Documents/projet_BioSceneMada/Internship_Report/data/mada_mod.RData")
np <- nrow(mod_all$model_spec$beta_start)
species <- colnames(mod_all$model_spec$presence_data)
## alpha_i of the first site
par(mfrow=c(1,2),oma=c(1, 0, 1.4, 0))
coda::traceplot(mod_all$mcmc.alpha[,1],main="Trace of alpha_1",cex.main=1.6)
coda::densplot(mod_all$mcmc.alpha[,1],main="Density of alpha_1", cex.main=1.6)
abline(v=mean(mod_all$mcmc.alpha[,1]),col="blue")
title(main="Random site effect alpha_1",outer=T,cex.main=1.8)
## V_alpha
coda::traceplot(mod_all$mcmc.V_alpha,main="Trace of V_alpha",cex.main=1.6)
coda::densplot(mod_all$mcmc.V_alpha,main="Density of V_alpha", cex.main=1.6)
abline(v=mean(mod_all$mcmc.V_alpha),col="blue")
title(main=" Variance of random site effects",outer=T, cex.main=1.8)
## beta_j of the first two species
for (j in 1:2) {
par(mfrow=c(2,2),oma=c(1, 0, 1.4, 0))
for (p in 1:np) {
coda::traceplot(mod_all$mcmc.sp[[j]][,p],
main=paste("Trace of", colnames(mod_all$mcmc.sp[[j]])[p]),cex.main=1.3)
coda::densplot(mod_all$mcmc.sp[[j]][,p],
main=paste("Density of", colnames(mod_all$mcmc.sp[[j]])[p]),cex.main=1.3)
abline(v=mean(mod_all$mcmc.sp[[j]][,p]),col="blue")
if(p==1) title(main=paste("Fixed species effect beta for species", species[j]), outer=T, cex.main=1.6)
}
}
## lambda_j of the first two species
n_latent <- mod_all$model_spec$n_latent
par(mfrow=c(n_latent,2),oma=c(1, 0, 1.4, 0))
for (j in 1:2) {
for (l in 1:n_latent) {
coda::traceplot(mod_all$mcmc.sp[[j]][,np+l],
main = paste("Trace of", colnames(mod_all$mcmc.sp[[j]])[np+l]),cex.main=1.6)
coda::densplot(mod_all$mcmc.sp[[j]][,np+l],
main = paste("Density of", colnames(mod_all$mcmc.sp[[j]])[np+l]),cex.main=1.6)
abline(v=mean(mod_all$mcmc.sp[[j]][,np+l]),col="blue")
}
title(main=paste("Factor loadings lambda for species ", species[j]),outer=T,cex.main=1.8)
}
## Latent variables W_i for one site
par(mfrow=c(2,2),oma=c(1, 0, 1.4, 0))
for (l in 1:n_latent) {
coda::traceplot(mod_all$mcmc.latent[[paste0("lv_",l)]][,1],
main = paste0(" Trace of W_1", l),cex.main=1.6)
coda::densplot(mod_all$mcmc.latent[[paste0("lv_",l)]][,1],
main = paste0(" Density of W_1", l),cex.main=1.6)
abline(v=mean(mod_all$mcmc.latent[[paste0("lv_",l)]][,1]),col="blue")
}
title(main="Latentes variables W_1", outer=T,cex.main=1.8)
## Deviance
par(mfrow=c(1,2),oma=c(1, 0, 1.5, 0))
coda::traceplot(mod_all$mcmc.Deviance,main="Trace",cex.main=1.6)
coda::densplot(mod_all$mcmc.Deviance,main="Density",cex.main=1.6)
abline(v=mean(mod_all$mcmc.Deviance),col="blue")
title(main = "Deviance",outer=T,cex.main=1.8)
# theta
par(mfrow=c(1,2))
hist(mod_all$probit_theta_latent,col="light blue", main = "probit(theta) estimated")
hist(mod_all$theta_latent, breaks=pretty, col="light blue", main = "theta estimated")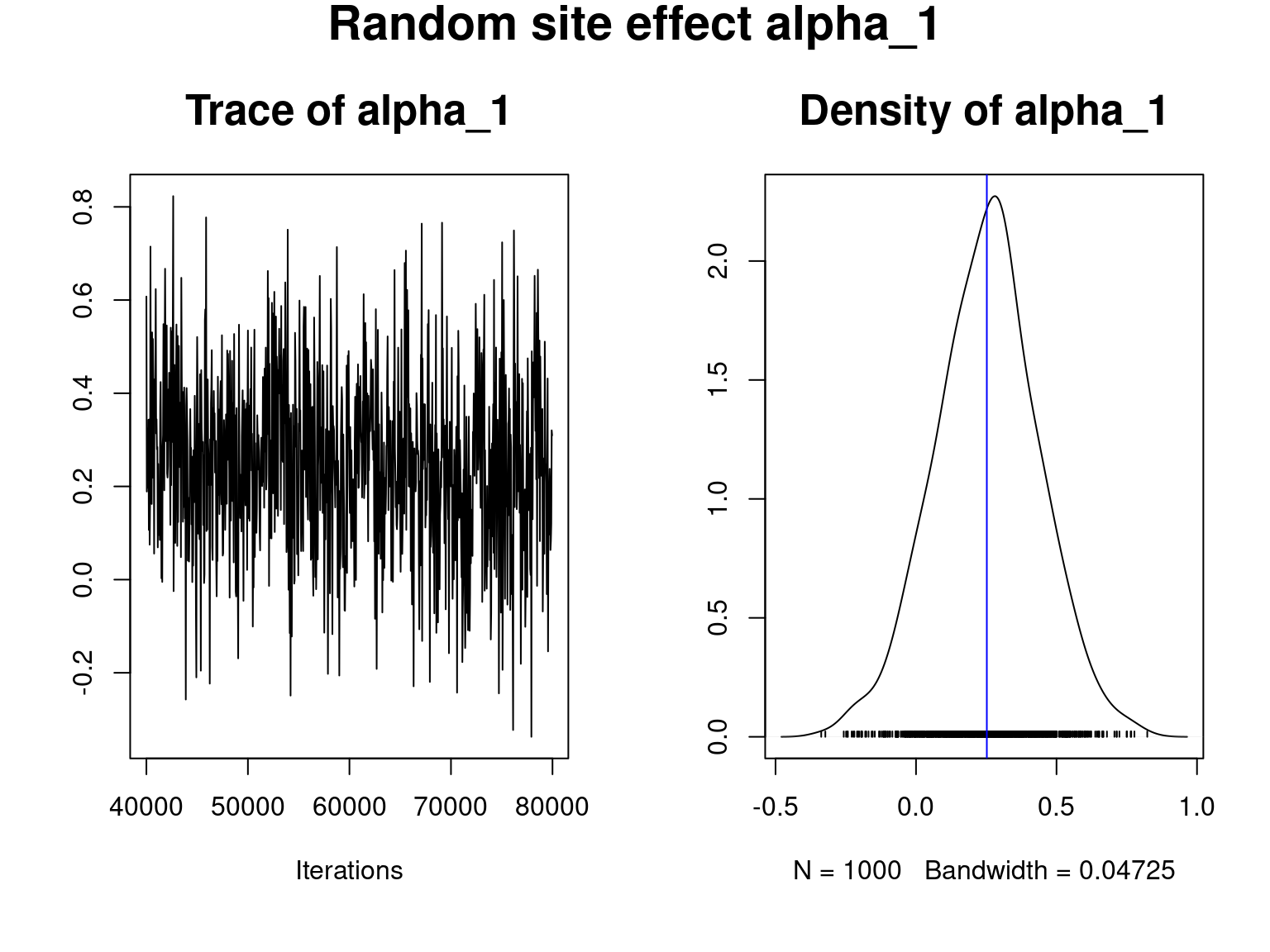
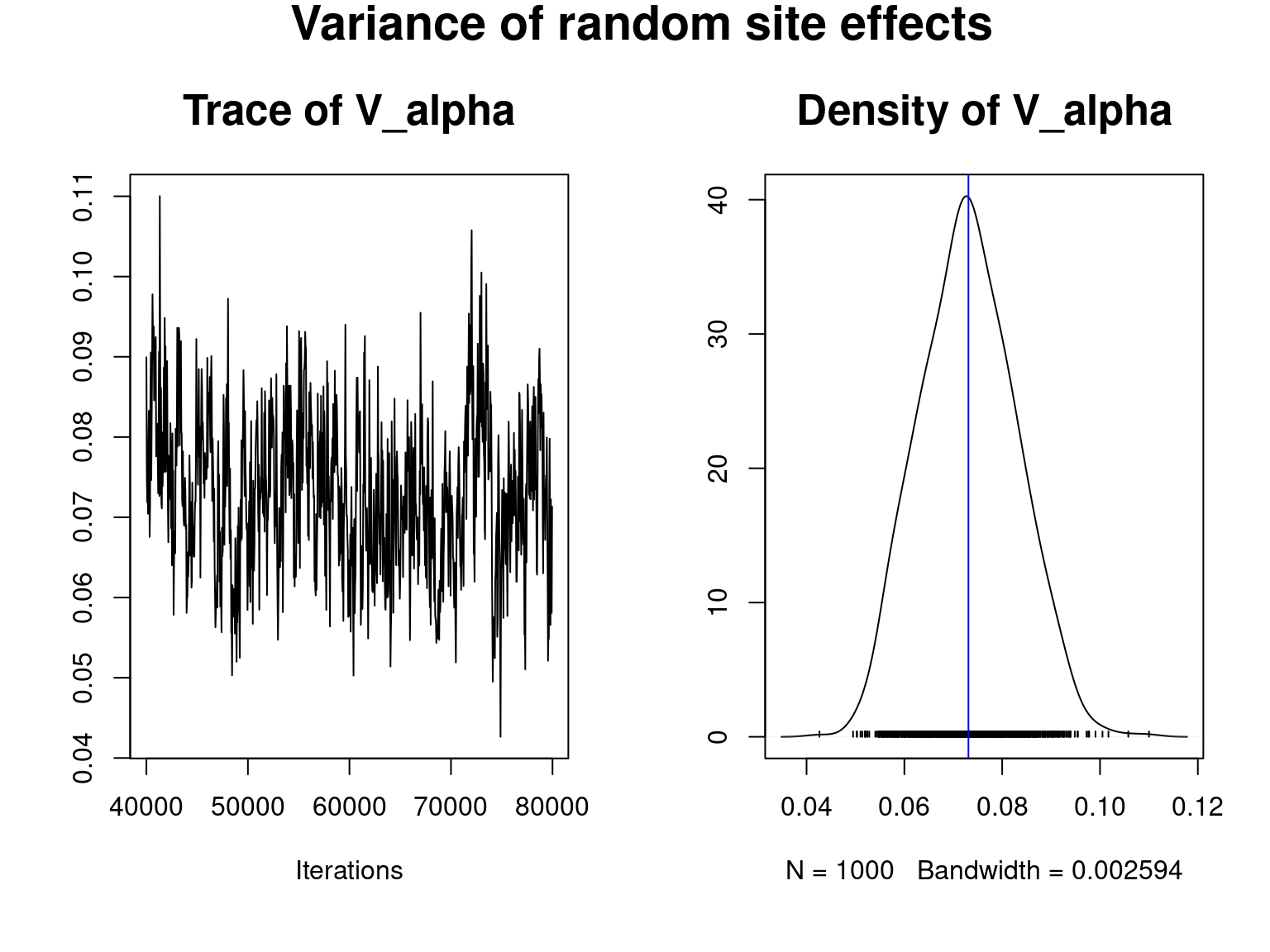
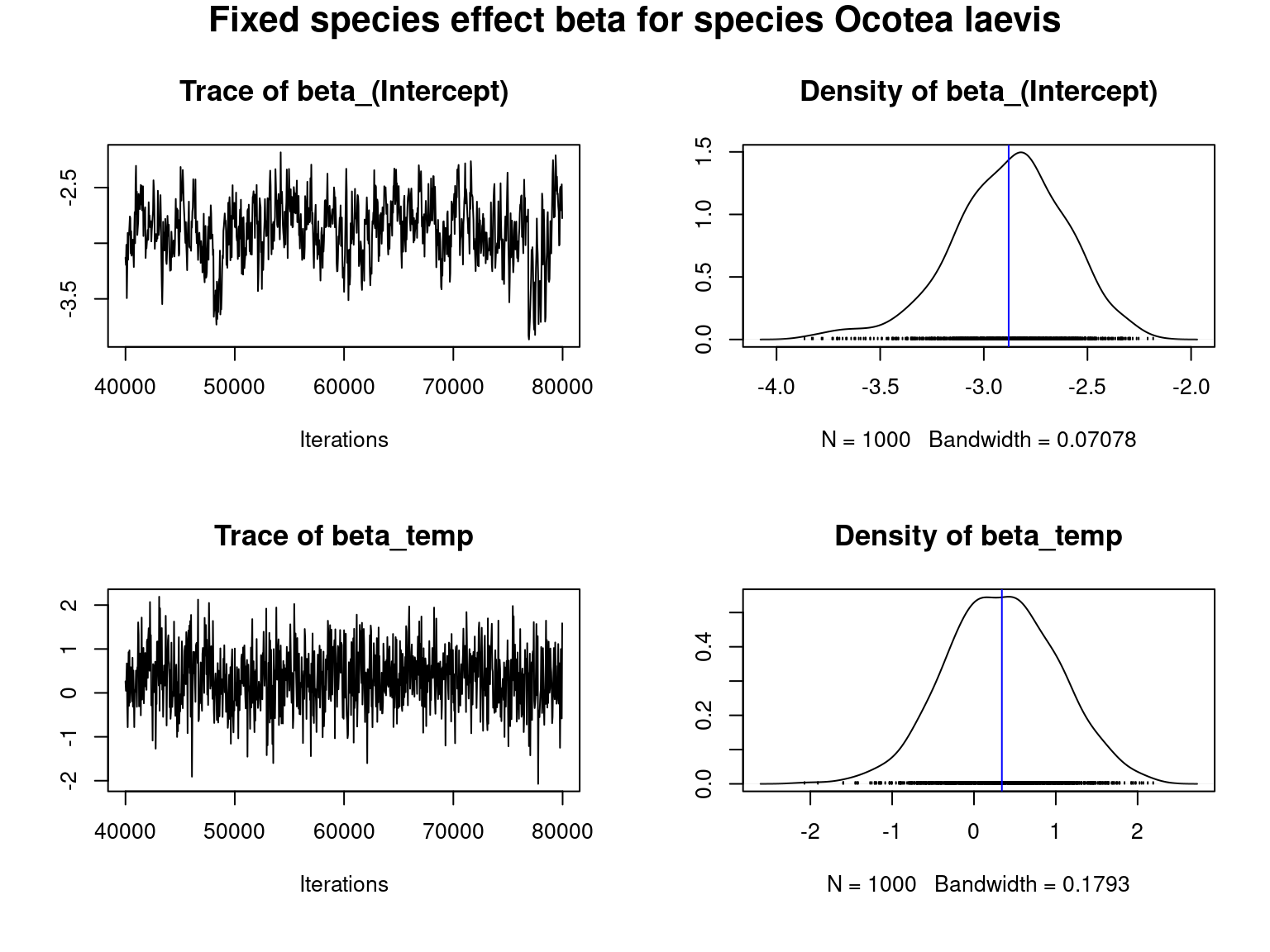
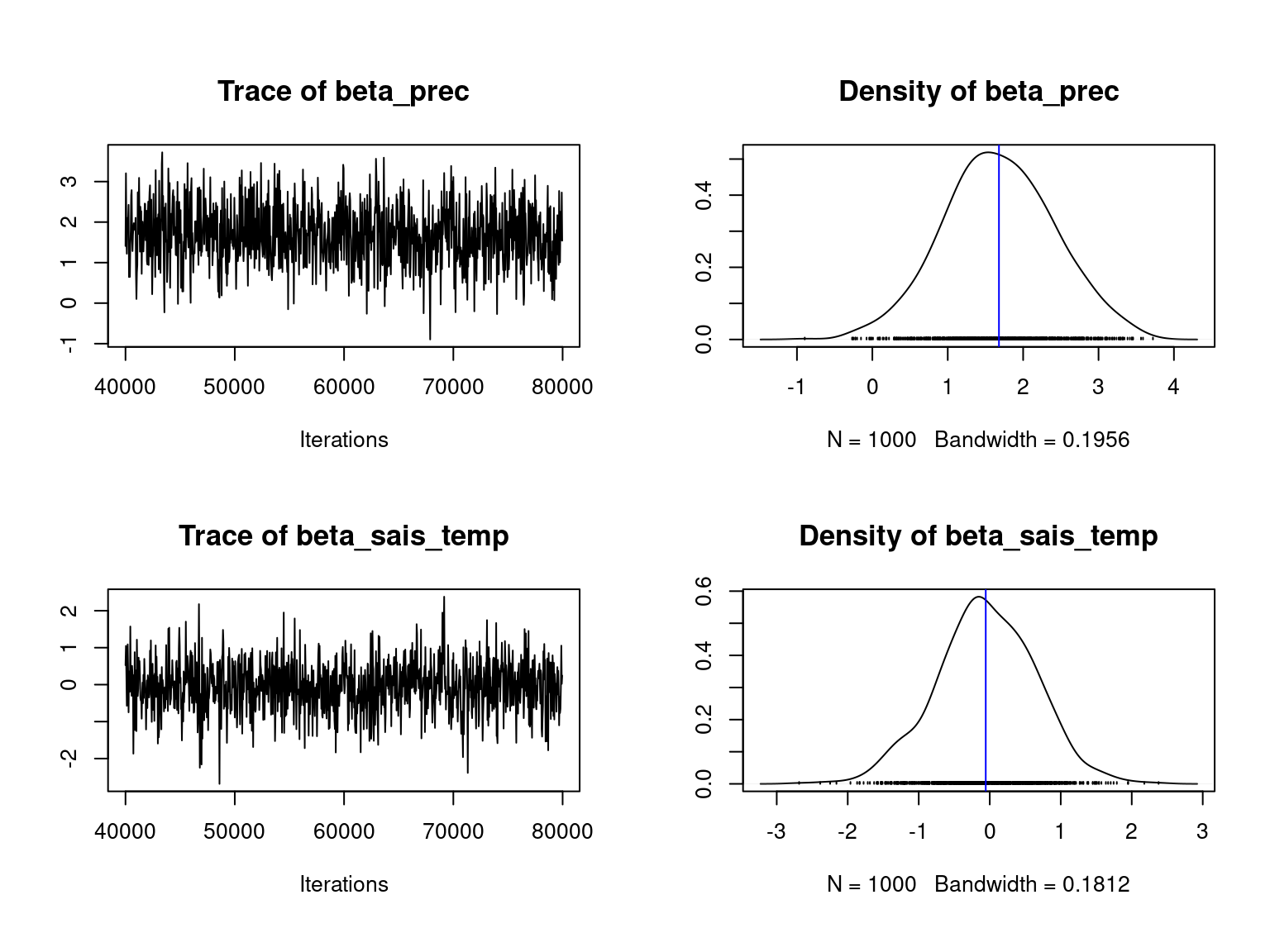
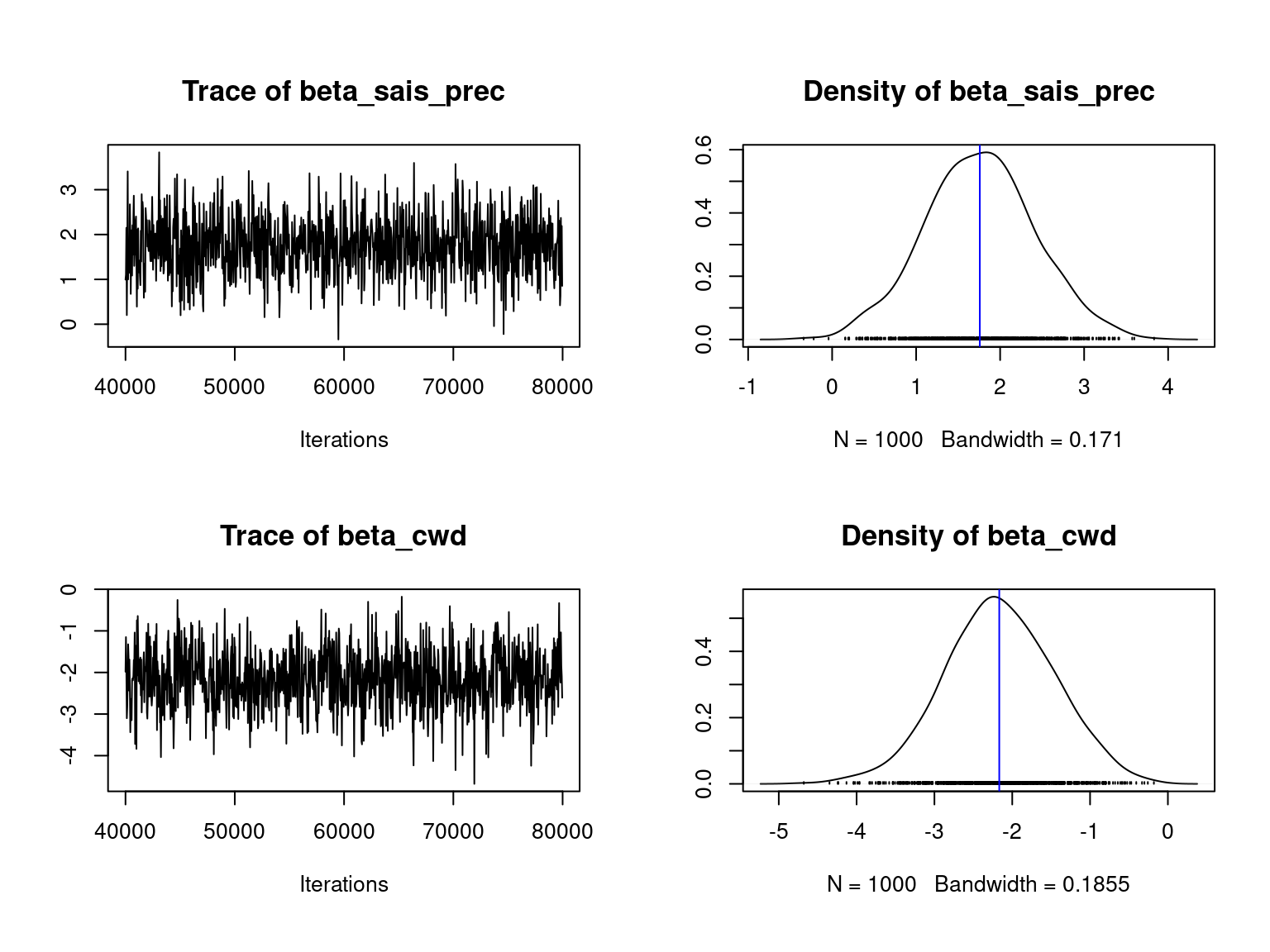
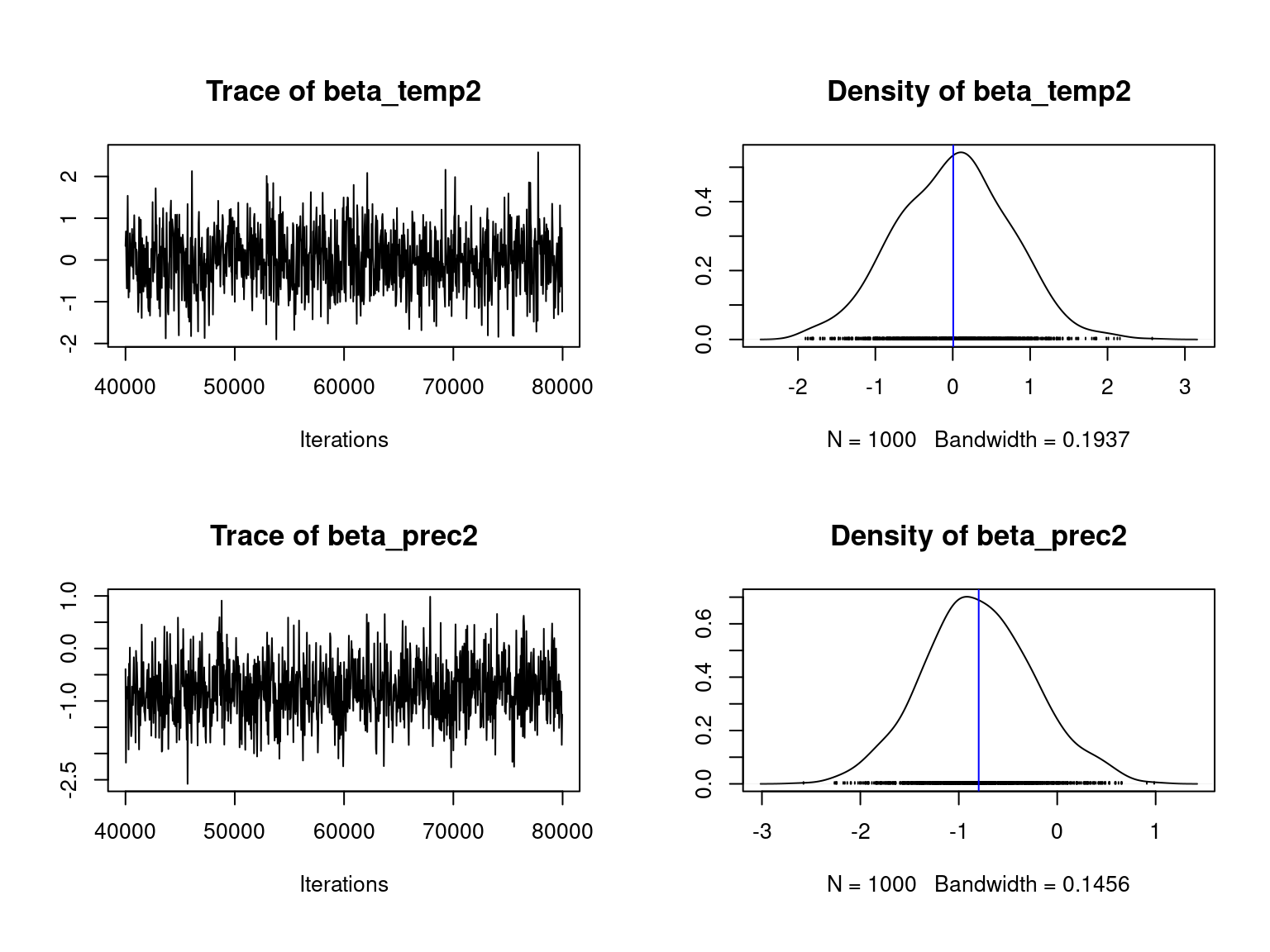
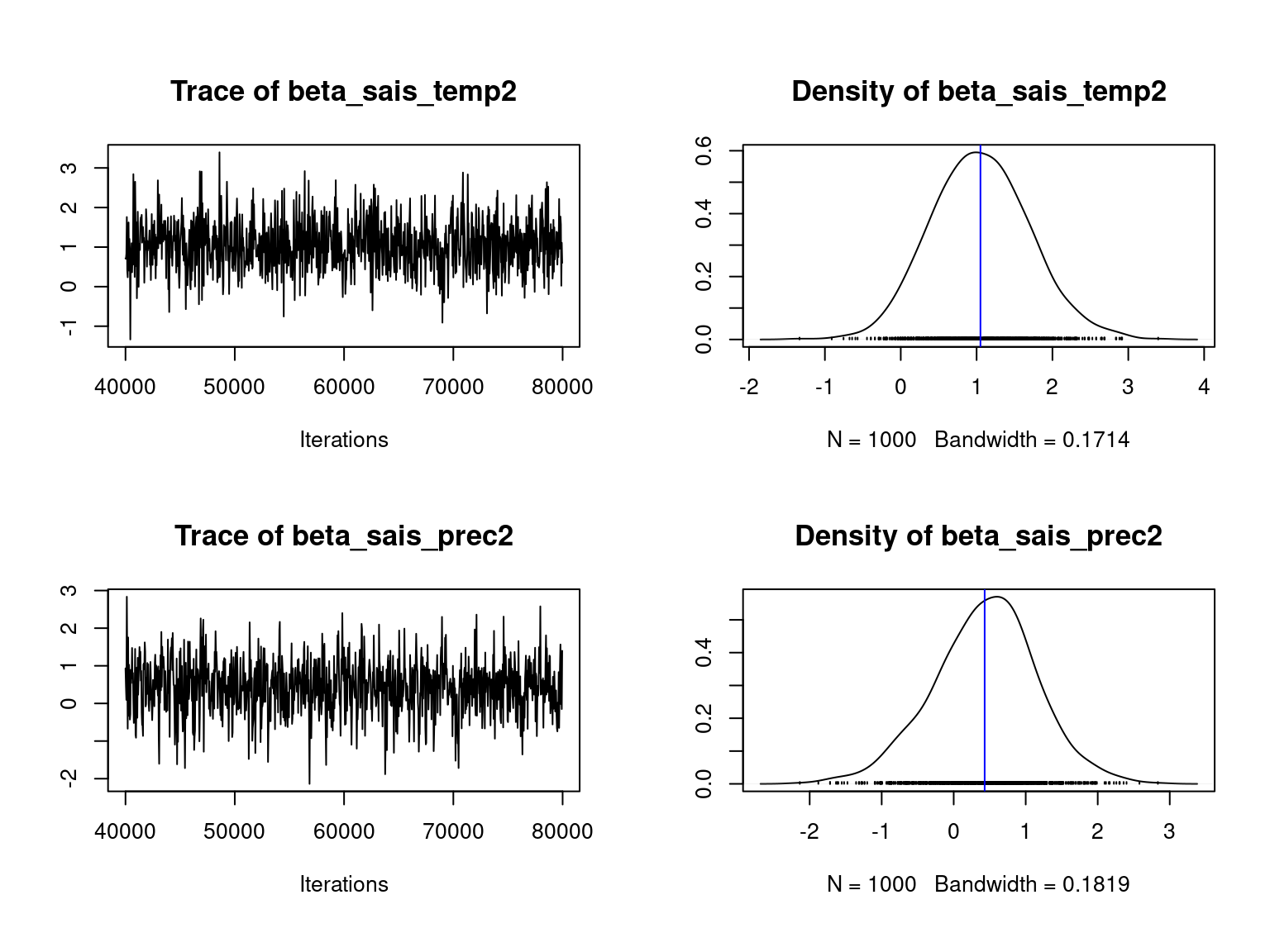
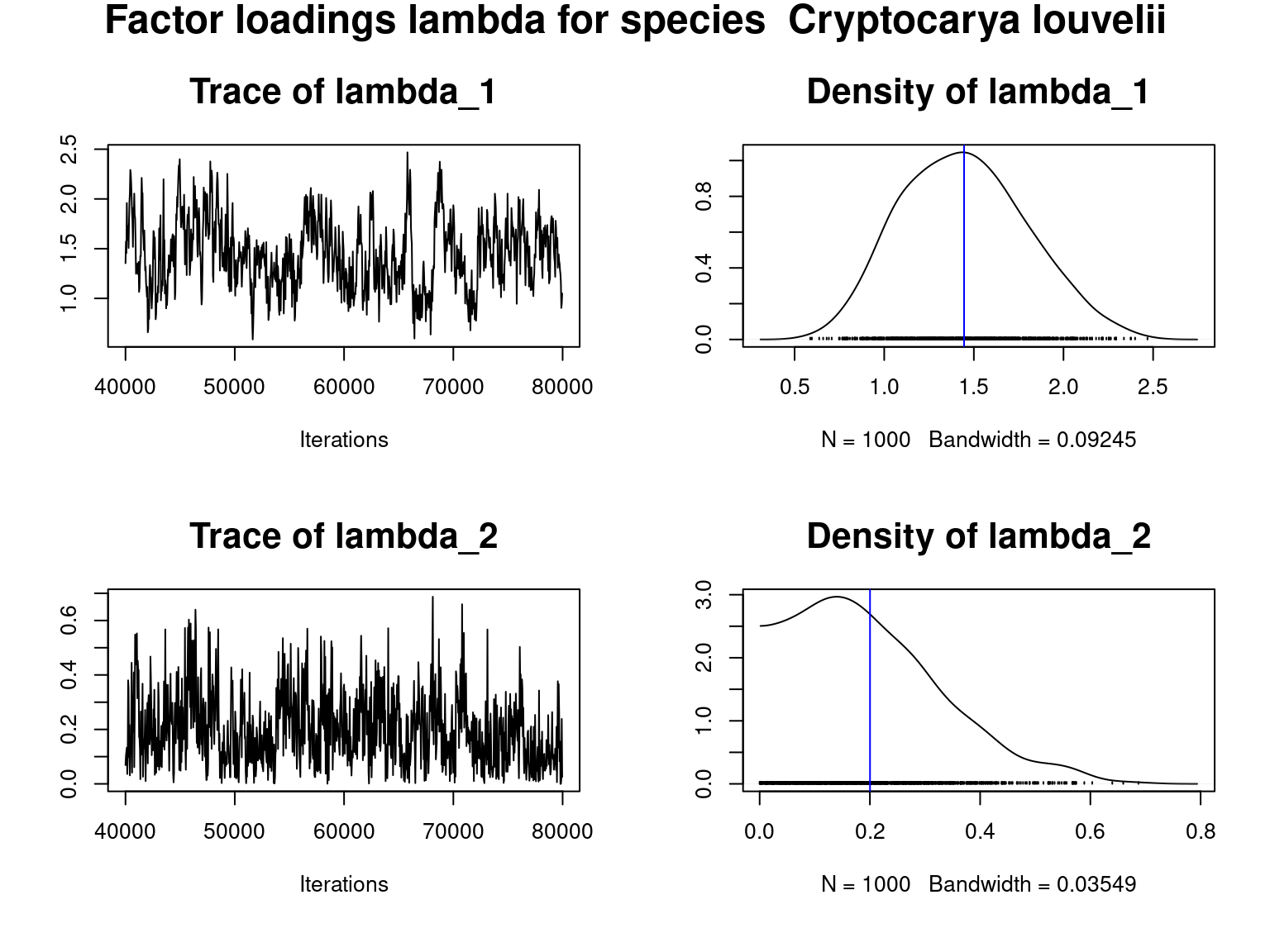
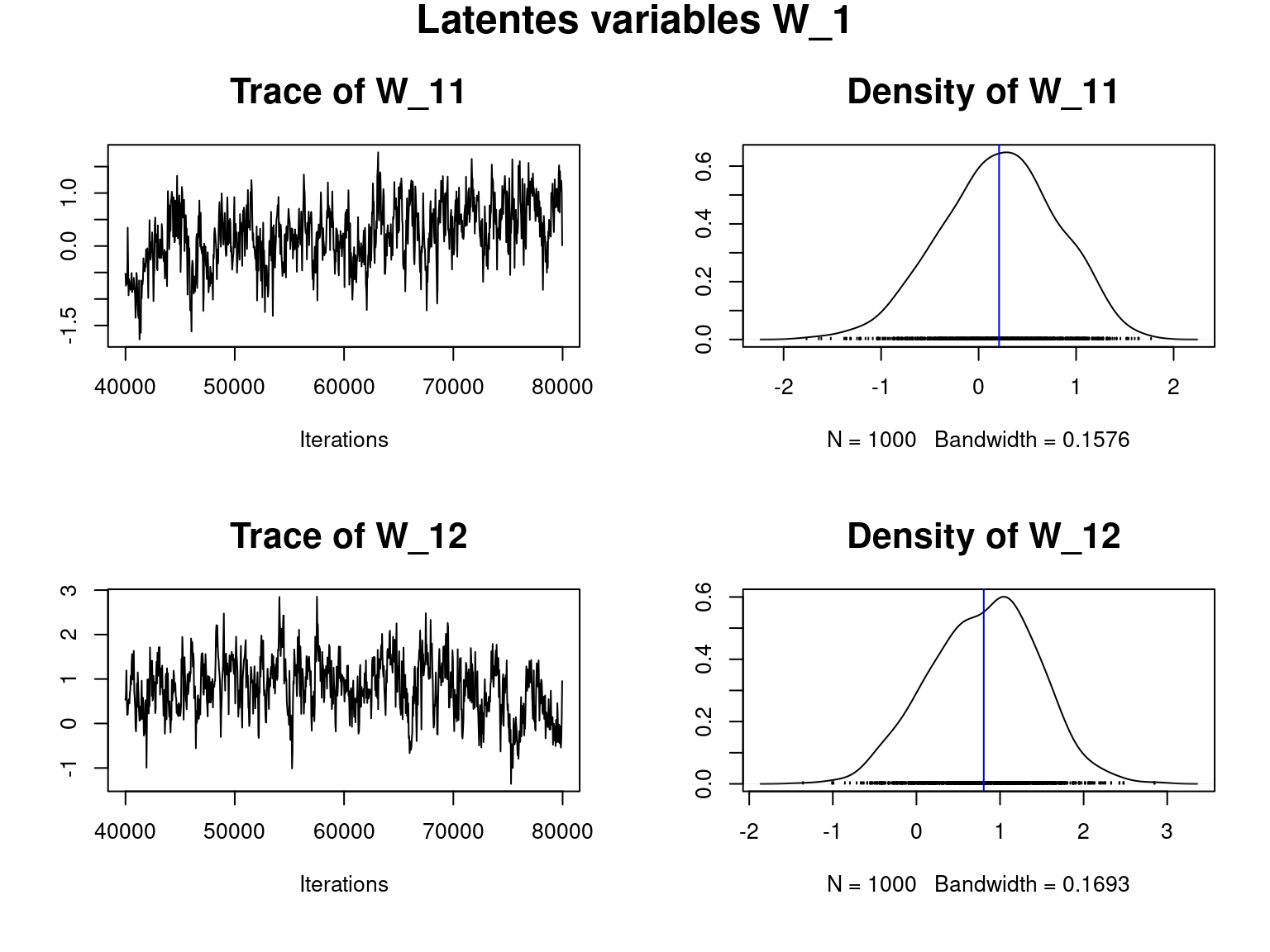
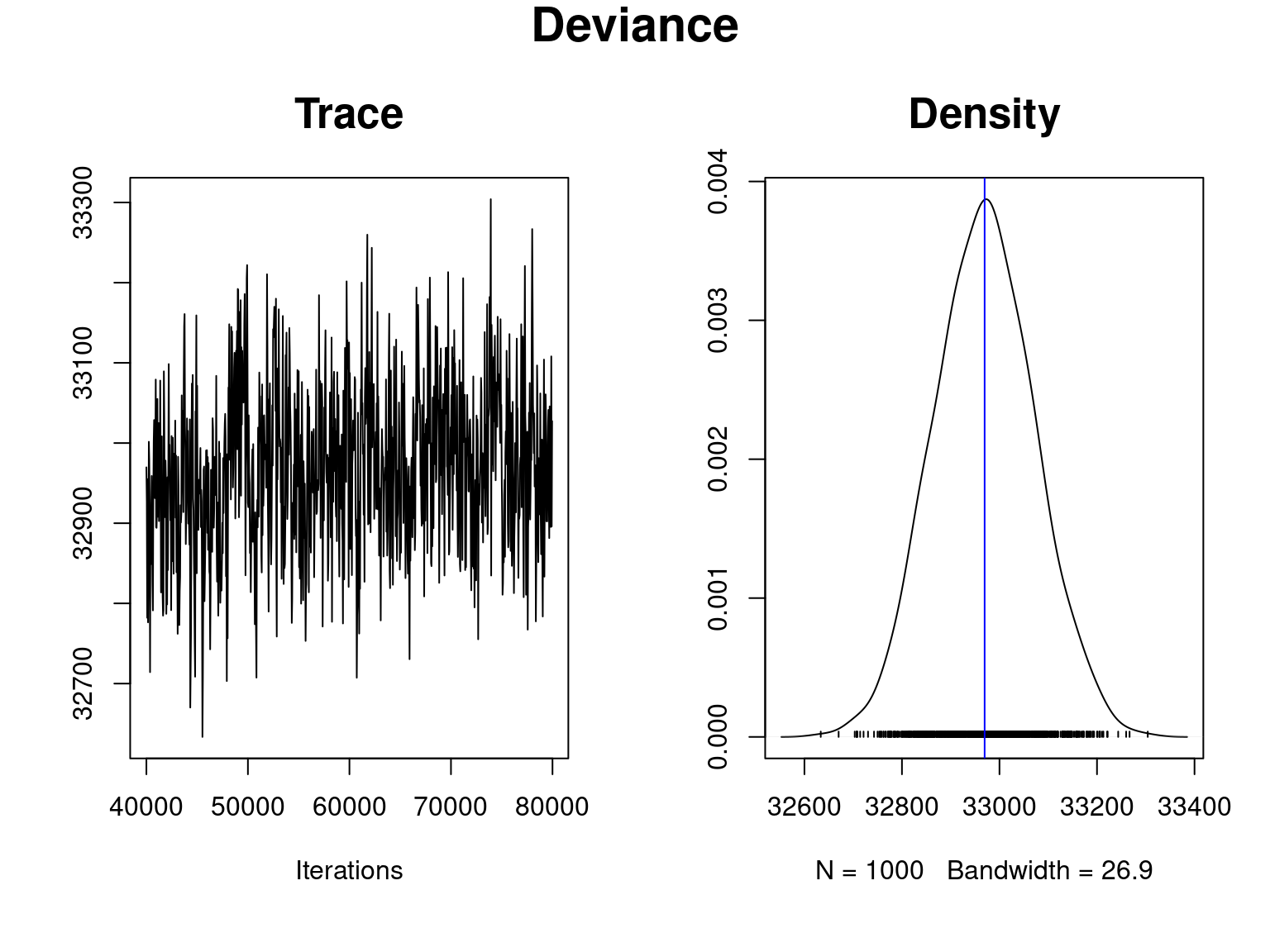
Overall, the traces and densities of the parameters indicate the convergence of the algorithm. Indeed, we observe on the traces that the values oscillate around averages without showing any upward or downward trend and we see that the densities are quite smooth and for most of them of Gaussian form.
4 Representation of results at inventory sites
4.1 Presence probabilities
load(file="~/Documents/projet_BioSceneMada/Internship_Report/data/output.RData")
theta_latent <- read.csv("~/Documents/projet_BioSceneMada/Internship_Report/data/theta_latent.csv")
data(madagascar, package="jSDM")
PA <- madagascar
xy <- terra::vect("/home/clement/Documents/projet_BioSceneMada/Internship_Report/data/coords.shp")
# Madagascar borders
Mada_borders <- terra::vect(output[[2]], layer = "gadm36_MDG_0")
Mada_borders <- terra::project(Mada_borders, terra::crs(xy))
# Observed presence absence
id_pres <- which(PA[, 1]==1)
id_abs <- which(PA[, 1]==0)
obs_pres <- terra::vect(terra::crds(xy[id_pres,]), type="point", crs=terra::crs(xy))
obs_abs <- terra::vect(terra::crds(xy[id_abs,]), type="point", crs=terra::crs(xy))
# Representation
par(mfrow=c(1,1))
terra::plot(Mada_borders, col="lightgray",
main ="Observed occurences of Ocotea laevis",
cex.main=1.4)
terra::points(obs_pres, pch=16, cex=1.1)
terra::points(obs_abs, pch=1)
legend("right", legend=c("presence","absence"), pch=c(16,1))
# Estimated probabilities of presence
theta_latent_sp <- terra::vect(cbind(terra::crds(xy), theta_latent),
geom=c("x", "y"), crs=terra::crs(xy))
# Representation
# define groups for mapping
cuts <- c(0,0.1,0.2,0.3,0.4,0.5,0.7,0.8,0.9)
col <- c('red3','red','orange','yellow', 'yellow green', 'green3', 'forest green','dark green')
terra::plot(Mada_borders, col="lightgray",
main ="Estimated probabilities of presence for Ocotea laevis",
cex.main=1.4)
terra::plot(theta_latent_sp, y=1, pch=20, cex=1.1,
legend="topright", plg=list(cex=1.01), add=TRUE, col=col,
type="interval", breaks=cuts)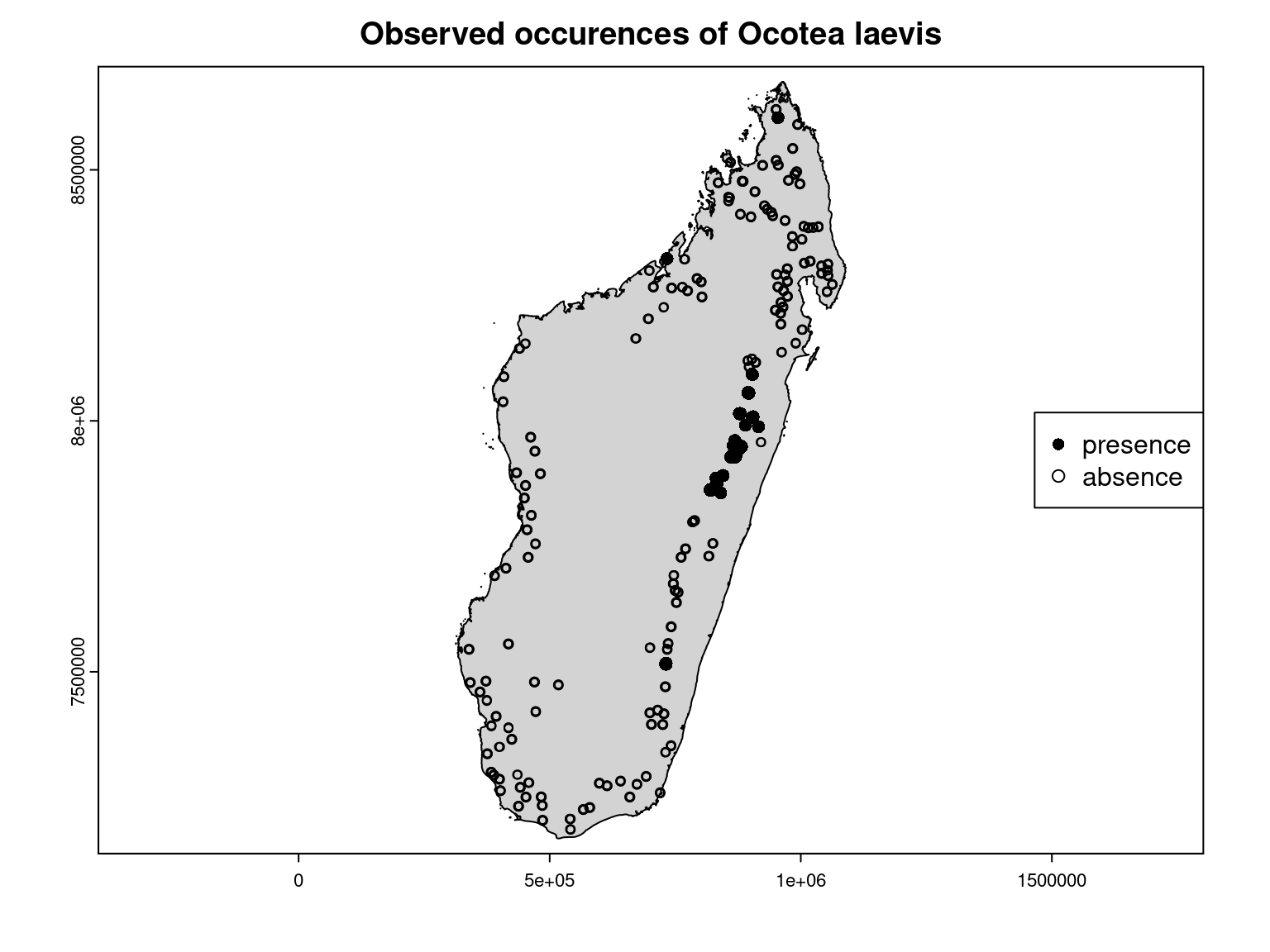
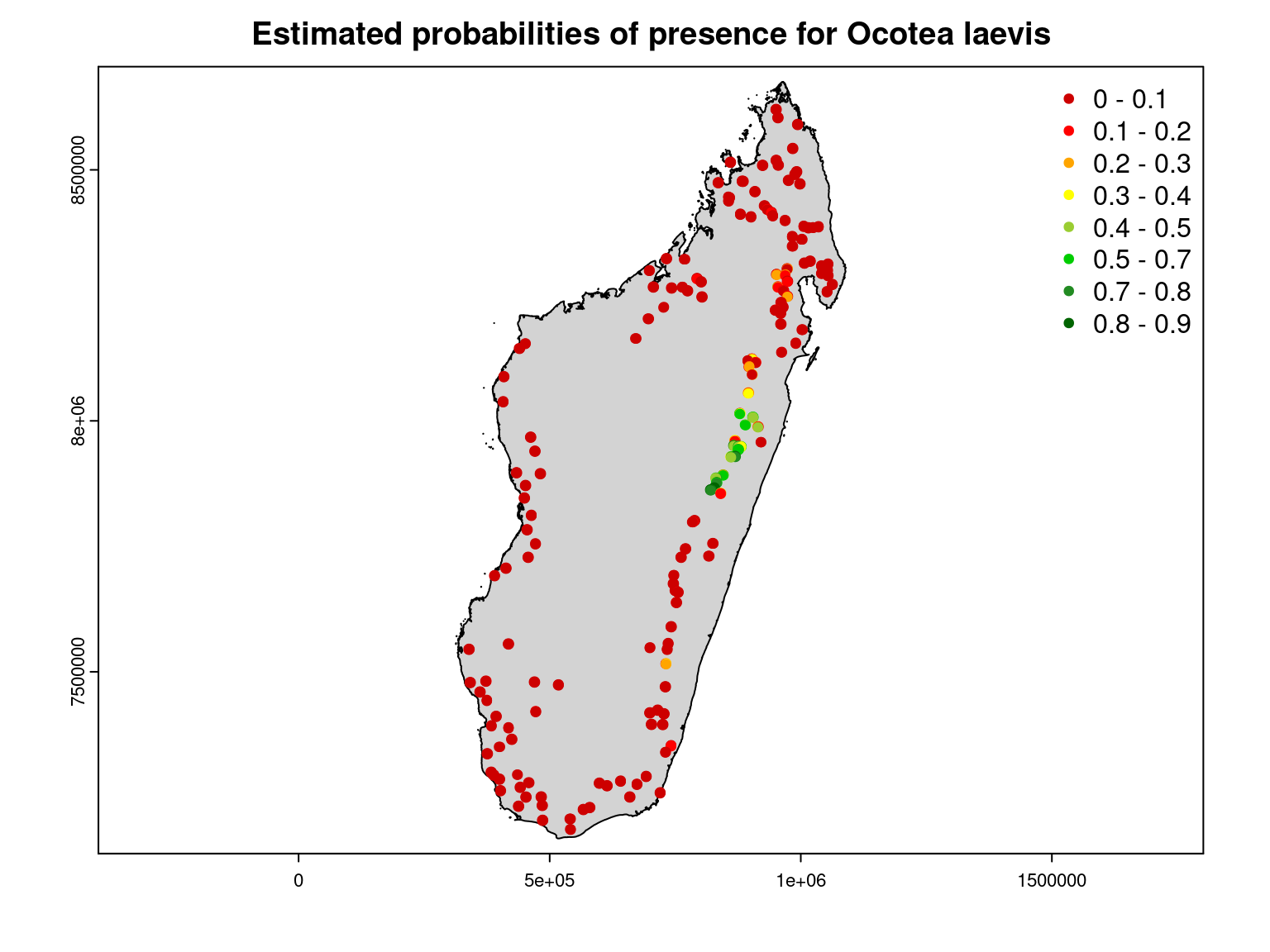
It can be observed that the inventory sites where this species was observed match those for which a high probability of presence was estimated by the JSDM.
4.2 Species richness
Species richness also called diversity \(\alpha\) reflects the number of species coexisting in a given environment and is computed by summing the number of species present on each site.
We spatially represent the species richness observed at each inventory site defined by \(R_i=\sum\limits_ {j=1}^{n_{species}} y_{ij}\) and the species richness estimated, following Scherrer, Mod & Guisan (2020), by summing the estimated occurrence probabilities of all species on each site: \(\widehat{R}_i=\sum\limits_ {j=1}^{n_{species}} \widehat{\theta}_{ij}\).
# Madagascar borders
Mada_borders <- terra::vect(output[[2]], layer = "gadm36_MDG_0")
Mada_borders <- terra::project(Mada_borders, terra::crs(xy))
# Representation of observed species richness
species_richness_obs <- data.frame(species_richness_obs=rowSums(PA))
species_richness_obs_sp <- terra::vect(cbind(terra::crds(xy), species_richness_obs),
geom=c("x","y"), crs=terra::crs(xy))
par(mfrow=c(1,1))
cuts <- c(0,2,4,8,12,16,20,24, ncol(theta_latent))
col <- c('red4','red','orange','yellow', 'yellow green', 'green3', 'forest green','dark green')
terra::plot(Mada_borders, col="lightgray",
main ="Observed species richness",
cex.main=1.4)
terra::plot(species_richness_obs_sp, 'species_richness_obs', breaks=cuts, col=col,
pch=20, cex=1.1, add=TRUE,
legend="topright", plg=list(cex=1.01), type="interval")
# Representation of estimated species richness
par(mfrow=c(1,1))
species_richness <- data.frame(species_richness= apply(theta_latent,1,sum))
species_richness_sp <- terra::vect(cbind(terra::crds(xy),
species_richness),
geom=c("x","y"), crs=terra::crs(xy))
terra::plot(Mada_borders, col="lightgray",
main ="Estimated species richness",
cex.main=1.4)
terra::plot(species_richness_sp, 'species_richness', col=col,
breaks=cuts, pch=20, cex=1.1, add=TRUE,
legend="topright", plg=list(cex=1.01), type="interval")
# Comparison between observed and estimated species richness at inventory sites
plot(species_richness_obs$species_richness_obs,
species_richness$species_richness,
main="Species richness",
xlab="observed", ylab="estimated",
cex.main=1.6, cex.lab=1.4, cex.axis=1.2)
abline(a=0,b=1,col='red')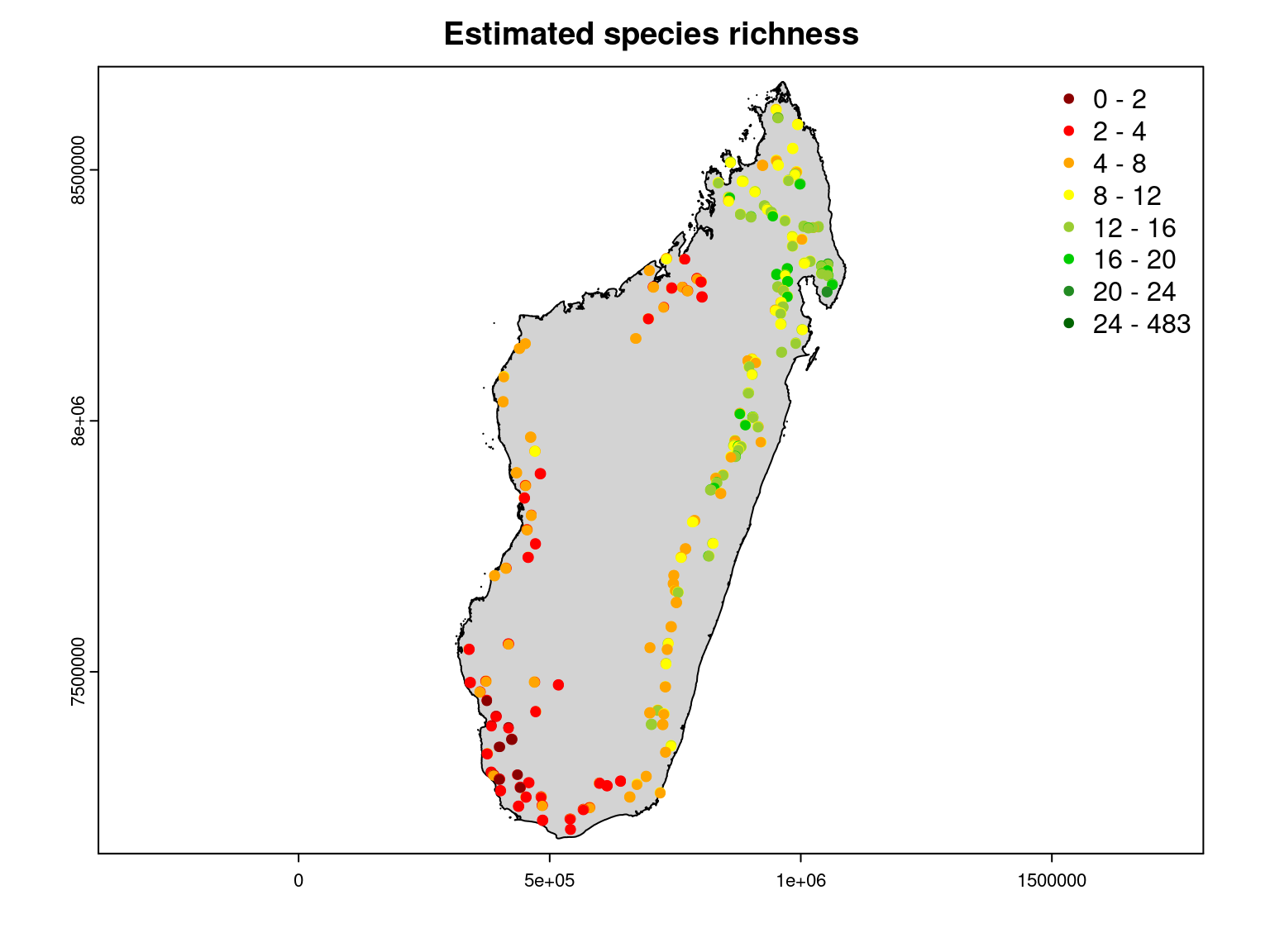
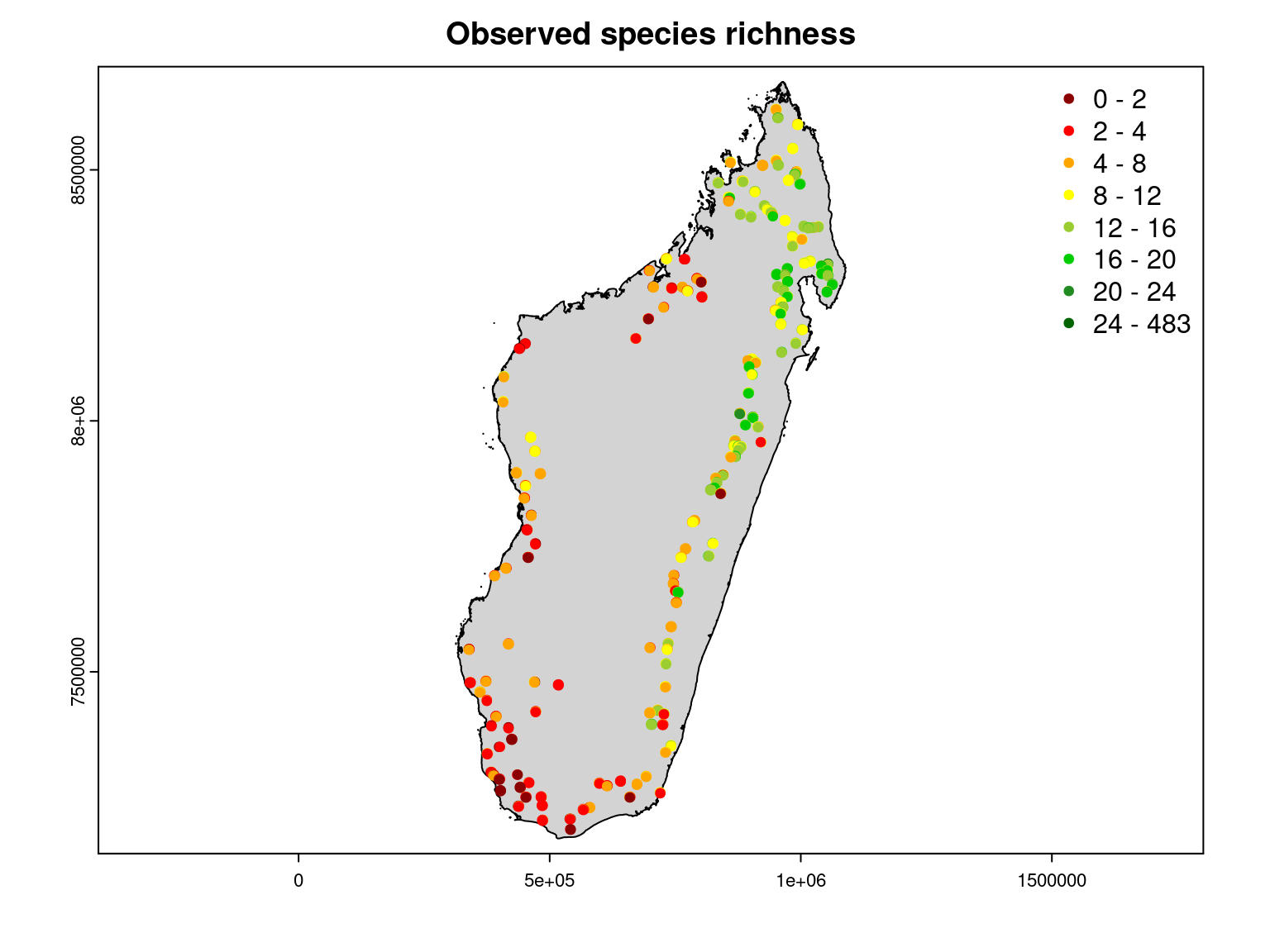
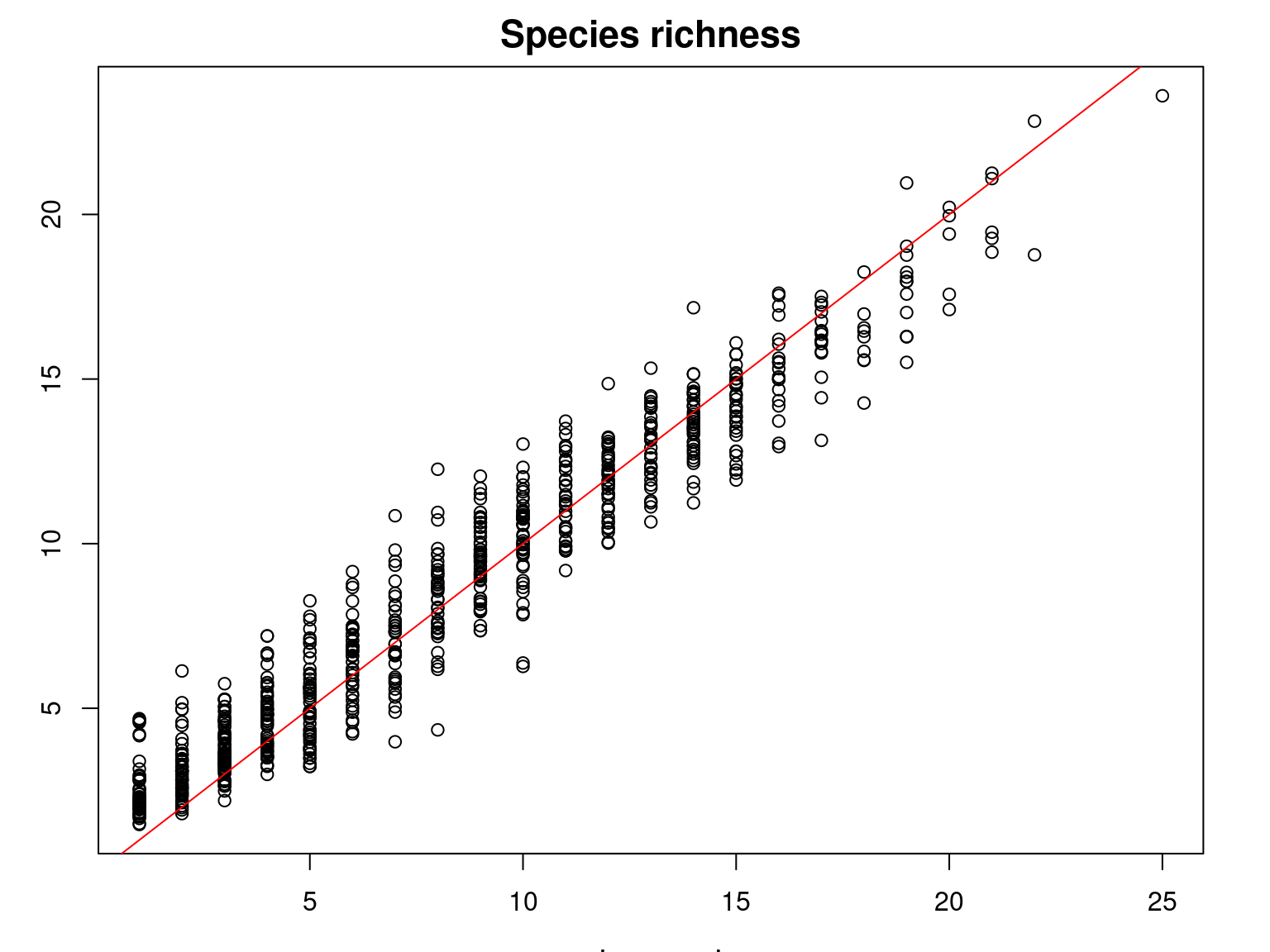
It can be seen that the observed species richness on the inventory sites corresponds fairly well to that estimated by summing the estimated probabilities of occurrence of all species on each site.
Moreover, we can see that the observed species richness is greater in the moist forest of the north-east of the island, particularly in the Masoala peninsula.
4.3 Residual correlation
After fitting the JSDM with latent variables, the full species residual correlation matrix \(R=(R_{ij})^{i=1,\ldots, n_{site}}_{j=1,\ldots, n_{species}}\) can be derived from the covariance in the latent variables such as : \[\Sigma_{ij} = \lambda_i^T .\lambda_j \], then we compute correlations from covariances : \[R_{i,j} = \frac{\Sigma_{ij}}{\sqrt{\Sigma _{ii}\Sigma _{jj}}}\].
load("~/Documents/projet_BioSceneMada/Internship_Report/data/mada_mod.RData")
n.species <- ncol(mod_all$model_spec$presence_data)
n.mcmc <- nrow(mod_all$mcmc.latent[[1]])
Tau.cor.arr <- matrix(NA,n.mcmc,n.species^2)
for(t in 1:n.mcmc) {
lv.coefs <- t(sapply(mod_all$mcmc.sp, "[", t, grep("lambda",colnames(mod_all$mcmc.sp[[1]]))))
Tau.mat <- lv.coefs %*% t(lv.coefs)
Tau.cor.mat <- cov2cor(Tau.mat)
Tau.cor.arr[t,] <- as.vector(Tau.cor.mat)
}
## Average over the MCMC samples
R <- matrix(apply(Tau.cor.arr,2,mean),n.species,byrow=F)
write.csv(R, file ="~/Documents/projet_BioSceneMada/Internship_Report/data/R.csv", row.names = F)We plot the top 50 estimated residual correlations between species based on their number of observed occurrences and environmental preferences.
# Forest inventory
data(madagascar, package="jSDM")
PA <- madagascar
# Species parameters
params_species <- read.csv(file = "~/Documents/projet_BioSceneMada/Internship_Report/data/params_species.csv")
# Residual correlation matrix R
R <- read.csv("~/Documents/projet_BioSceneMada/Internship_Report/data/R.csv")
colnames(R) <- rownames(R) <- make.names(params_species$species)
R <- as.matrix(R)
library(viridis)
jSDM::plot_associations(R, circleBreak=TRUE, occ=PA, top=50,
main="Species-species association sorted after their frequency",
cols_association=viridis::viridis(10),
cols_occurrence=viridis::magma(10),
species_order="frequency")
# Average of MCMC samples of species effect beta except the intercept
effects = params_species[,grep("beta", colnames(params_species))[-1]]
np <- ncol(effects)
# Add absolute quadratic and linear effects of each environmental variable
effects <- abs(effects[,1:(np/2)]) + abs(effects[,(np/2 +1):np])
colnames(effects) <- gsub("beta_", "",colnames(effects))
jSDM::plot_associations(R, env_effect=effects, top=50,
main="Species-species association sorted after their main environmental effect",
cols_association=viridis::viridis(10),
species_order="main env_effect")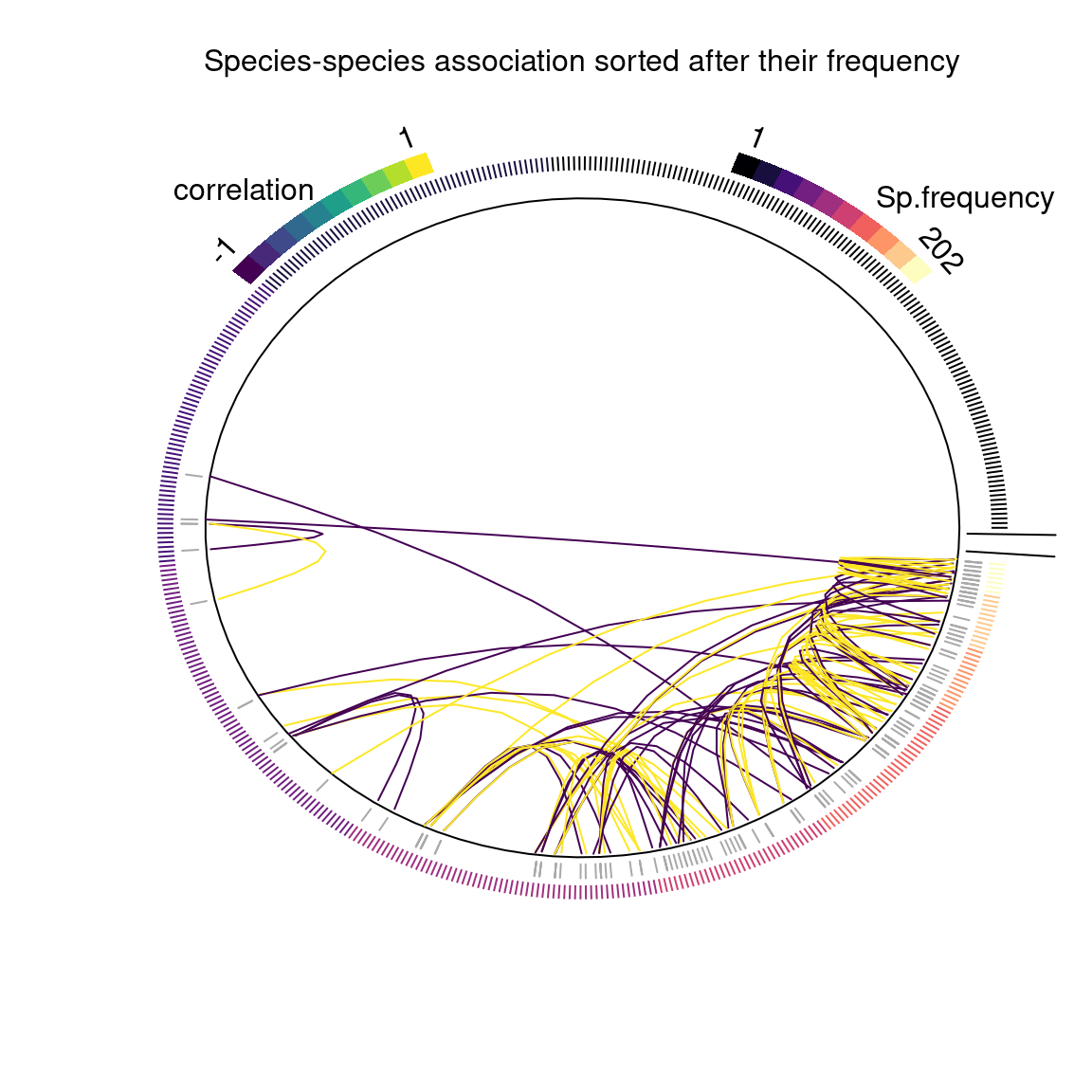
The figure above shows the correlations between species, with the 483 species sorted according to the number of sites where they occur out of the 751 inventoried.
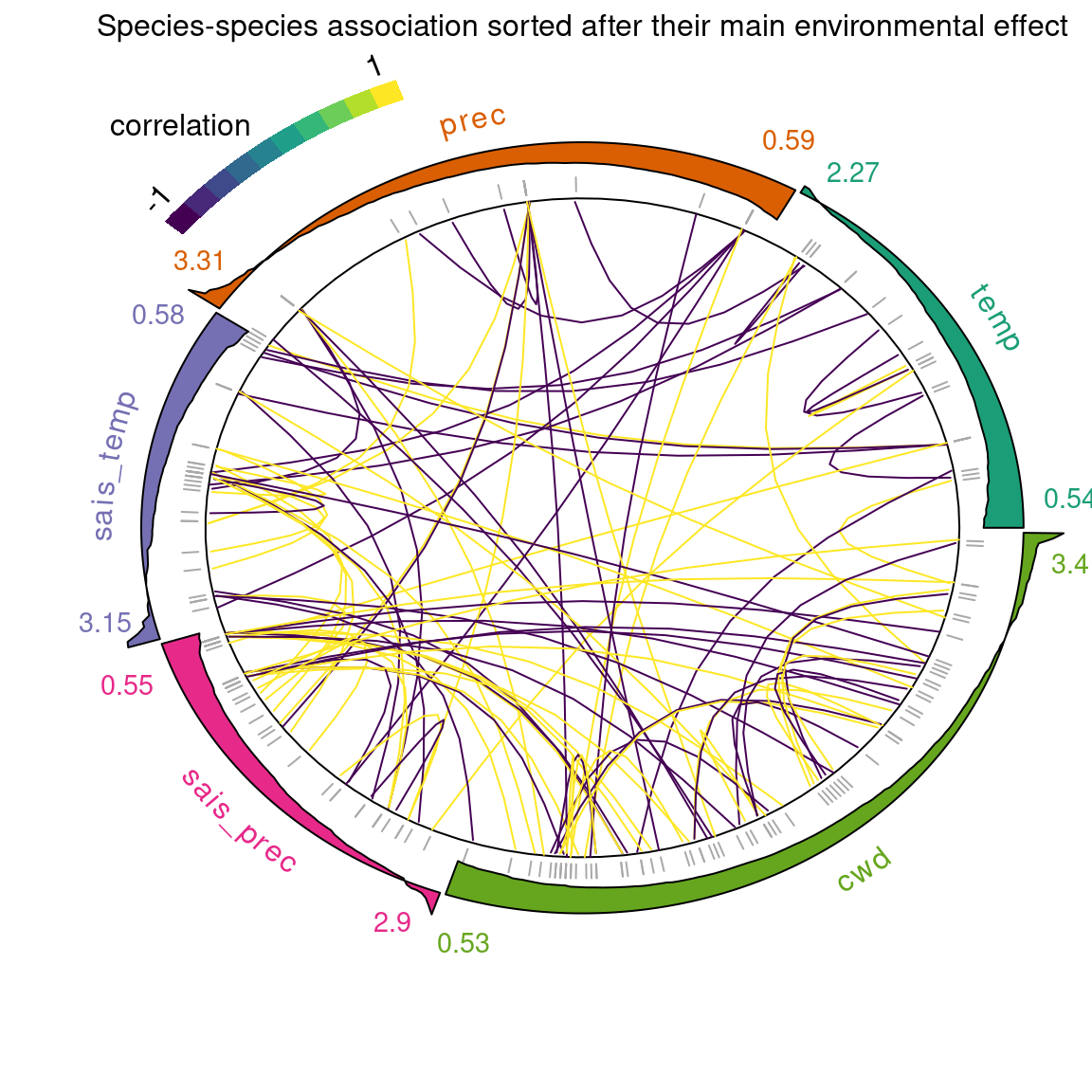
The figure above shows the same covariance structure but with the species sorted according to their largest environmental coefficients (\(\beta\)) (the outer ring shows the distribution of environmental effect for species within the sample).
This representation of associations between species allows us to observe the positive or negative correlations between species which can be interpreted in terms of positive or negative influence of the presence of a species on the probability of occurrence of another.
5 Intrapolation of parameters between inventory sites
5.1 Assessing spatial auto-correlation of estimated site’s parameters
The presence of a spatial structure where observations close to each other are more similar than those far away (spatial auto-correlation) is a prerequisite for the application of geostatistics and from the previous spatial representations it seems to be satisfied.
However, we verify the presence of spatial auto-correlation within our site parameters by calculating Moran indices, using ape::Moran.I() function, on the one hand, and by representing the variograms corresponding to site effects (\(\alpha\)) and latent variables (\(W1\) and \(W2\)) on the other.
5.1.1 Moran’s I autocorrelation coefficient
# Import sites parameters
params_sites <- read.csv("~/Documents/projet_BioSceneMada/Internship_Report/data/params_sites.csv")
# inventory sites coordinates in UTM38S projection
xy <- terra::vect("/home/clement/Documents/projet_BioSceneMada/Internship_Report/data/coords.shp")
# Compute spatial autocorrelation between inventory site's (Moran's I)
tab <- matrix(NA, ncol=4, nrow=3)
rownames(tab) <- c("alpha", "W1", "W2")
colnames(tab) <- c("observed", "expected", "sd", "p.value")
## Random site effect alpha
alpha.dists <- as.matrix(dist(terra::crds(xy)))
alpha.dists.inv <- 1/alpha.dists
diag(alpha.dists.inv) <- 0
# Using package ape (add in jSDM's Suggests )
tab["alpha",] <- unlist(ape::Moran.I(params_sites$alphas,
weight=alpha.dists.inv, scaled=TRUE))
# Using pacakge terra (no p-value returned)
# terra::autocor(params_sites$alphas, w=alpha.dists.inv,
# method="moran")
# First latent axis W1
# Compute spatial autocorrelation between inventory site's (Moran's I)
W1.dists <- as.matrix(dist(terra::crds(xy)))
W1.dists.inv <- 1/W1.dists
diag(W1.dists.inv) <- 0
tab["W1",] <- unlist(ape::Moran.I(params_sites$W1, weight=W1.dists.inv,
scaled=TRUE))
# Second latent axis W2
W2.dists <- as.matrix(dist(terra::crds(xy)))
W2.dists.inv <- 1/W2.dists
diag(W2.dists.inv) <- 0
tab["W2",] <- unlist(ape::Moran.I(params_sites$W2, weight=W2.dists.inv, scaled=TRUE))
# Table of results
knitr::kable(tab, row.names=TRUE, digits=4, booktabs=TRUE, align = 'c') %>%
kableExtra::kable_styling(latex_options=c("HOLD_position","striped"),
full_width=FALSE) %>%
kableExtra::save_kable(file="~/Documents/jSDM/vignettes/Madagascar_files/Moran.I_mada.png")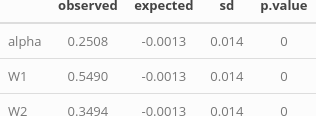
We can see that for each type of parameter, the p-value is null, then we can reject the null hypothesis, i.e. the absence of spatial auto-correlation within these parameters.
In the table above, the value “observed” corresponds to the computed Moran’s I and the value “expected” to the expected value of I under the null hypothesis.
5.1.2 Variograms
library(gstat)
# Import sites parameters
params_sites <- read.csv("~/Documents/projet_BioSceneMada/Internship_Report/data/params_sites.csv")
# inventory sites coordinates in UTM38S projection
xy <- terra::vect("/home/clement/Documents/projet_BioSceneMada/Internship_Report/data/coords.shp")
# Coordinates in km
params_sites[, c("x","y")] <- terra::crds(xy)/1000
### variogram fo ordinary kriging
# alpha
var_alpha <- gstat::variogram(alphas~1, ~x+y, data=params_sites)
mv_alpha <- gstat::fit.variogram(var_alpha, vgm("Sph"),
fit.kappa=TRUE)
plot(var_alpha, model=mv_alpha, main="Variogram of site effect alpha")
# W1
var_W1 <- gstat::variogram(W1~1, ~x+y, data=params_sites)
mv_W1 <- gstat::fit.variogram(var_W1, vgm("Gau"), fit.kappa=TRUE)
plot(var_W1, model=mv_W1, main="Variogram of latent variable W1")
# W2
var_W2 <- gstat::variogram(W2~1, ~x+y, data=params_sites)
mv_W2 <- gstat::fit.variogram(var_W2, vgm("Sph"), fit.kappa=TRUE)
plot(var_W2, model=mv_W2, main="Variogram of latent variable W2")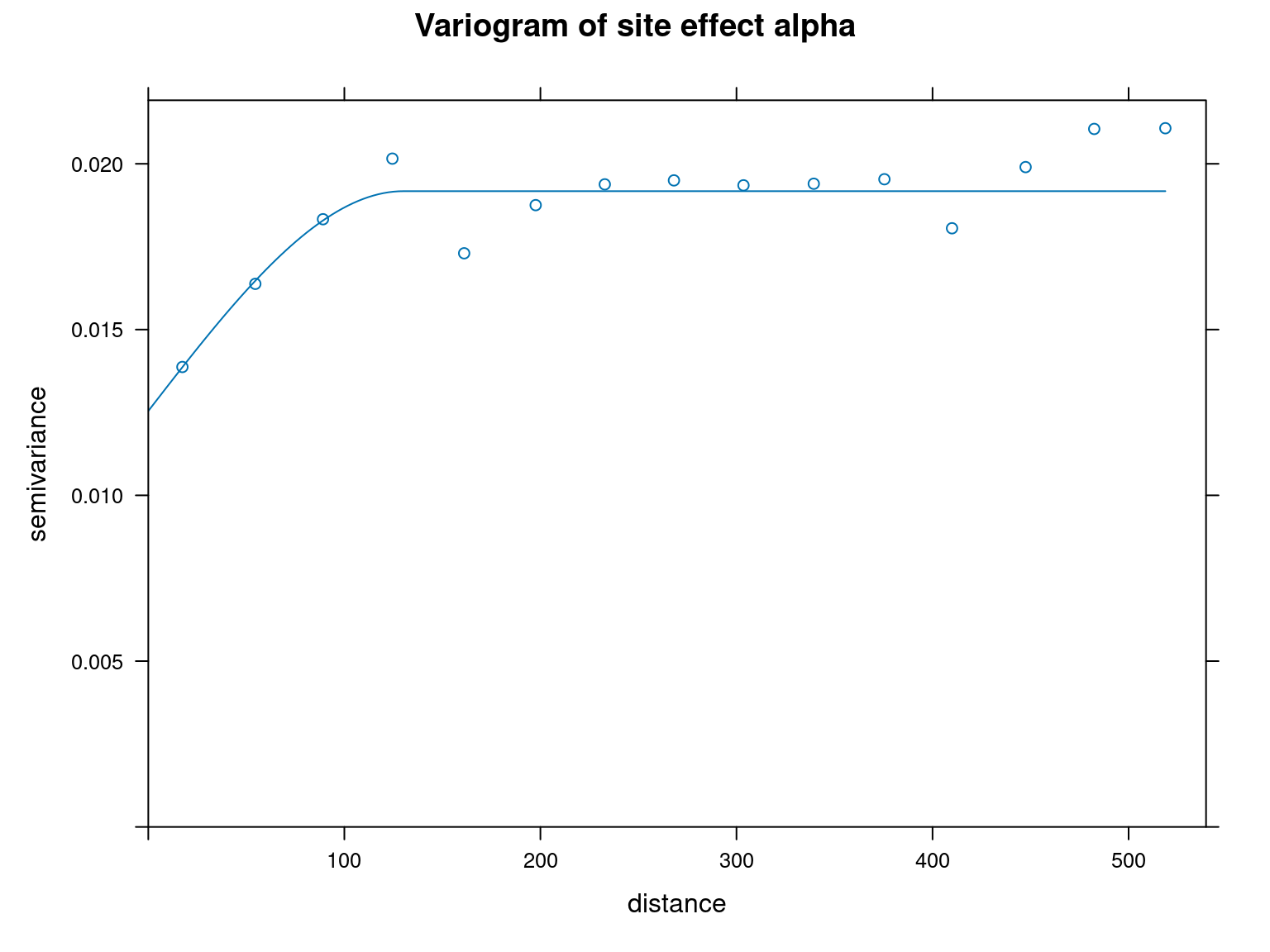
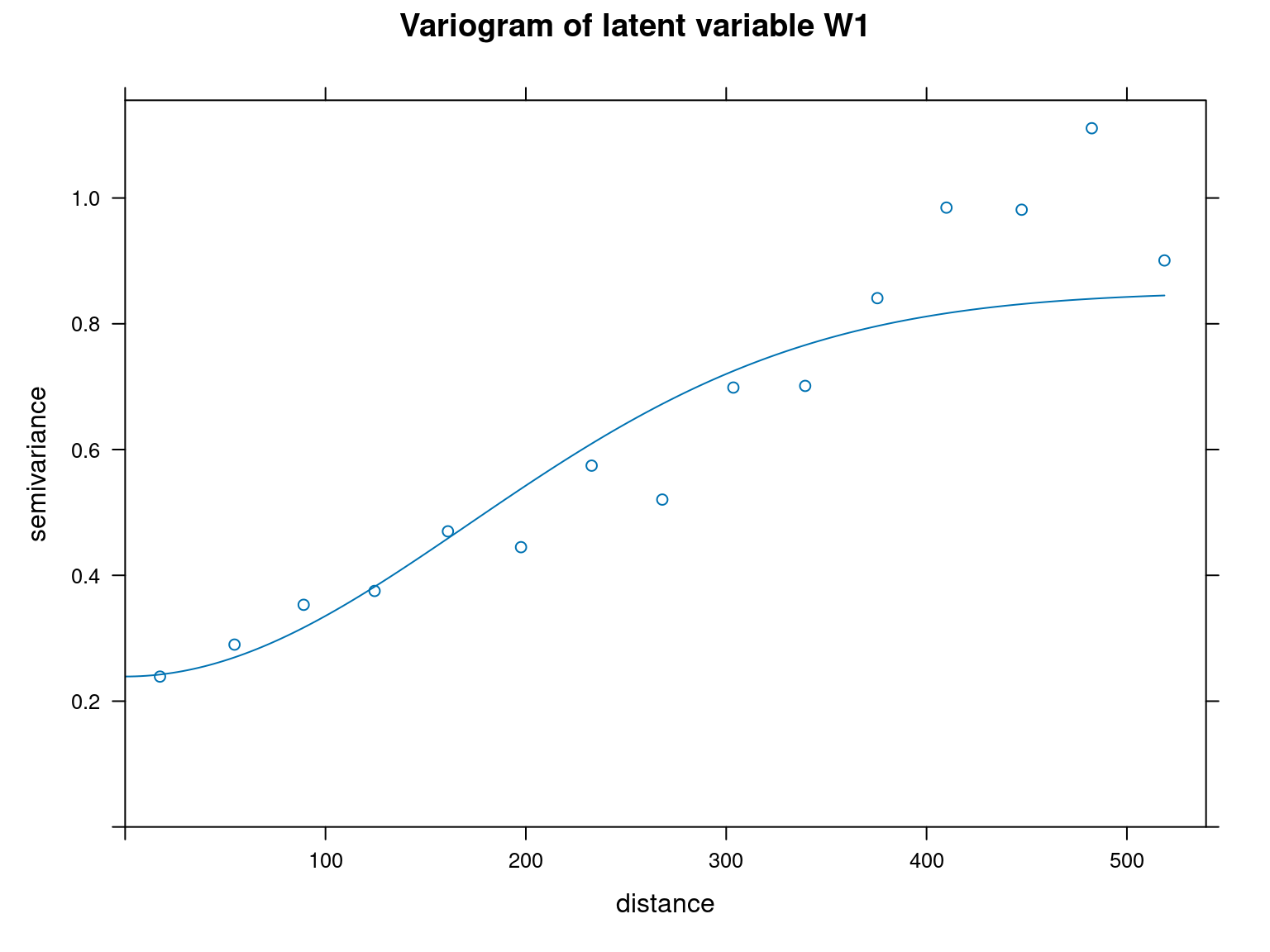
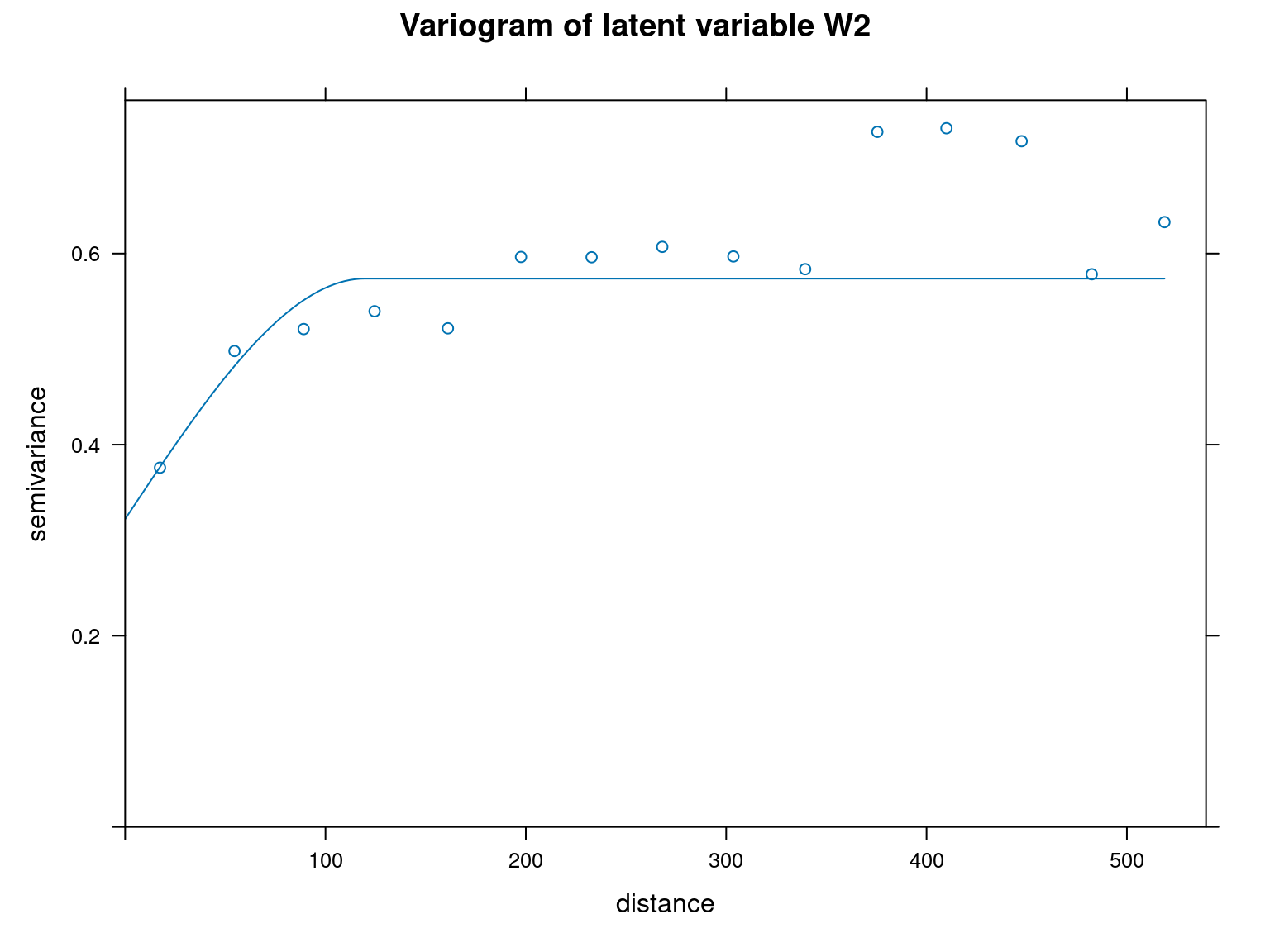
We can see from the variograms above that the semi-variance is lower for the closest points and increases with distance between points for each parameter type. This shows that there is spatial auto-correlation.
5.2 Interpolation using regularized spline with tension
Thus, it is possible to interpolate sites’ parameters for the whole island from those estimated for the inventory plots using the spatial interpolation method called regularized spline with tension (RST) from GRASS GIS software via rgrass7 R package.
This method is described in the article (Mitášová & Hofierka 1993).
5.2.1 Random site effect \(\alpha\)
## Initialize GRASS
setwd("~/Documents/jSDM/vignettes")
Sys.setenv(LD_LIBRARY_PATH=paste("/usr/lib/grass78/lib", Sys.getenv("LD_LIBRARY_PATH"),sep=":"))
library(rgrass7)
# use a georeferenced raster
system('grass -c ~/Documents/projet_BioSceneMada/Internship_Report/data/scaled_clim.tif grassdata/interpolation')
# connect to grass database
initGRASS(gisBase="/usr/lib/grass78",
gisDbase="grassdata",
location="interpolation", mapset="PERMANENT",
override=TRUE)We interpolate the random site effect at Madagascar scale using RST method.
library(rgrass7)
# Import sites parameters
params_sites <- read.csv("~/Documents/projet_BioSceneMada/Internship_Report/data/params_sites.csv")
# inventory sites coordinates in UTM38S projection
xy <- terra::vect("/home/clement/Documents/projet_BioSceneMada/Internship_Report/data/coords.shp")
# alpha
alpha_sp <- terra::vect(data.frame(alpha=params_sites$alphas, terra::crds(xy)),
geom=c("x","y"), crs=terra::crs(xy))
rgrass7::write_VECT(alpha_sp, "alpha", flags="overwrite")
# Re-sample with RST
# for punctual data use function v.surf.rst
system("v.surf.rst --overwrite --verbose -t tension=3 input=alpha zcolumn=alpha \\
smooth=0.0 elevation=alpha_rst")
# Export
system("r.out.gdal --overwrite input=alpha_rst \\
output=Madagascar_cache/alpha_rst.tif type=Float32 \\
createopt='compress=lzw,predictor=2'")
# Representation
alpha_rst <- terra::rast("/home/clement/Documents/jSDM/vignettes/Madagascar_cache/alpha_rst.tif")
# Data restricted to Madagascar's borders
borders <- terra::vect(output[[2]], layer="gadm36_MDG_0")
borders <- terra::project(borders, terra::crs(alpha_rst))
alpha_rst <- terra::mask(alpha_rst, borders)
# terra::writeRaster(alpha_rst,
# filename="/home/clement/Documents/jSDM/vignettes/Madagascar_cache/alpha_rst.tif",
# gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)
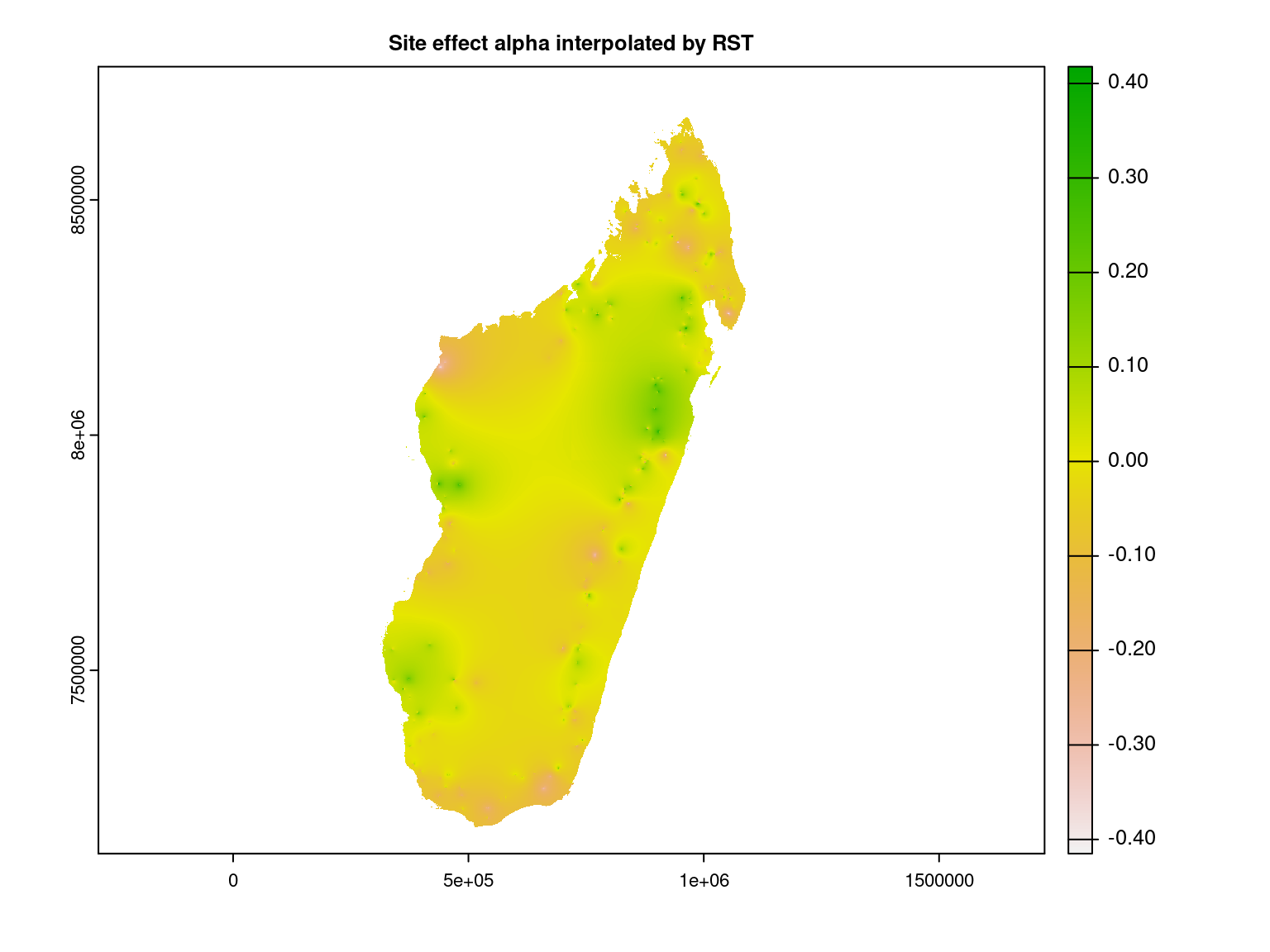
terra::plot(alpha_rst, main="Site effect alpha interpolated by RST")
alpha_rst_xy <- terra::extract(alpha_rst, xy)[,"alpha_rst"]
plot(alpha_rst_xy, params_sites$alphas,
xlab="alpha interpolated by RST",
ylab="alpha estimated by JSDM",
main="Random site effect")
abline(a=0, b=1, col='red')
# Center interpolated site effect
alpha_rst_centered <- terra::app(alpha_rst, fun=scale, scale=FALSE)
names(alpha_rst_centered) <- names(alpha_rst)
terra::plot(alpha_rst_centered, main="Site effect alpha interpolated by RST")
alpha_rst_centered_xy <- terra::extract(alpha_rst_centered, xy)[,"alpha_rst"]
plot(alpha_rst_centered_xy, params_sites$alphas,
xlab="alpha interpolated by RST",
ylab="alpha estimated by JSDM",
main="Random site effect")
abline(a=0, b=1, col='red')
terra::writeRaster(alpha_rst_centered, "Madagascar_cache/alpha_rst_centered.tif",
gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)We represent the random site effect interpolated at Madagascar scale.
5.2.2 Latent variables \(W\)
We interpolate the first axis of latent variables at the Madagascar scale using the RST method.
# W1
W1_sp <- terra::vect(data.frame(W1=params_sites$W1, terra::crds(xy)),
geom=c("x","y"), crs=terra::crs(xy))
rgrass7::write_VECT(W1_sp, "W1", flags="overwrite")
# Re-sample with RST
# Note: use mask=Madagascar to save computation time
# for punctual data use function v.surf.rst
system("v.surf.rst --overwrite --verbose -t tension=3 input=W1 zcolumn=W1 \\
smooth=0.0 elevation=W1_rst")
# Export
system("r.out.gdal --overwrite input=W1_rst \\
output=Madagascar_cache/W1_rst.tif type=Float32 \\
createopt='compress=lzw,predictor=2'")
# Representation
W1_rst <- terra::rast("Madagascar_cache/W1_rst.tif")
# Data restricted to Madagascar's borders
borders <- terra::vect(output[[2]], layer="gadm36_MDG_0")
borders <- terra::project(borders, terra::crs(W1_rst))
W1_rst <- terra::mask(W1_rst, borders)
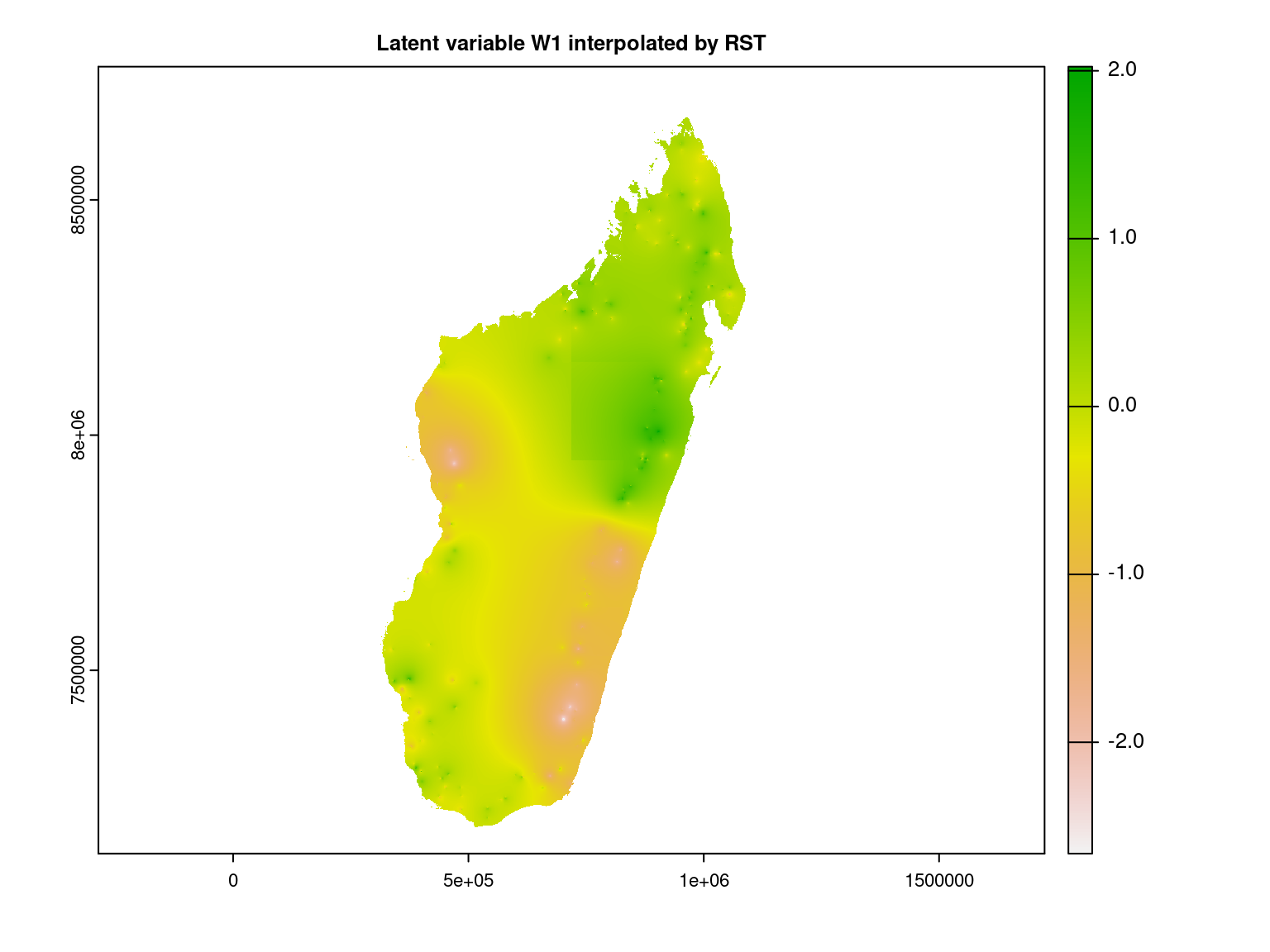
terra::plot(W1_rst, main="Latent variable W1 interpolated by RST")
W1_rst_xy <- terra::extract(W1_rst, xy)[, "W1_rst"]
plot(W1_rst_xy, params_sites$W1,
xlab="W1 interpolated by RST",
ylab="W1 estimated by JSDM",
main="First latent axis")
abline(a=0, b=1, col='red')
# Center interpolated first latent axis
W1_rst_centered <- terra::app(W1_rst, scale, scale=FALSE)
names(W1_rst_centered) <- names(W1_rst)
terra::plot(W1_rst_centered, main="First latent axis interpolated by RST")
W1_rst_centered_xy <- terra::extract(W1_rst_centered, xy)[,"W1_rst"]
plot(W1_rst_centered_xy, params_sites$W1,
xlab="W1 interpolated by RST",
ylab="W1 estimated by JSDM",
main="First latent axis")
abline(a=0, b=1, col='red')
terra::writeRaster(W1_rst_centered, "Madagascar_cache/W1_rst_centered.tif",
gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)We represent the first latent variable interpolated at Madagascar scale.
We interpolate the second axis of latent variables at the Madagascar scale using the RST method.
# W2
W2_sp <- terra::vect(data.frame(W2=params_sites$W2, terra::crds(xy)),
geom=c("x","y"), crs=terra::crs(xy))
rgrass7::write_VECT(W2_sp, "W2", flags="overwrite")
# Re-sample with RST
# Note: use mask=Madagascar to save computation time
# for punctual data use function v.surf.rst
system("v.surf.rst --overwrite --verbose -t tension=3 input=W2 zcolumn=W2 \\
smooth=0.0 elevation=W2_rst")
# Export
system("r.out.gdal --overwrite input=W2_rst \\
output=Madagascar_cache/W2_rst.tif type=Float32 \\
createopt='compress=lzw,predictor=2'")
# Representation
W2_rst <- terra::rast("Madagascar_cache/W2_rst.tif")
# Data restricted to Madagascar's borders
borders <- terra::vect(output[[2]], layer="gadm36_MDG_0")
borders <- terra::project(borders, terra::crs(W2_rst))
W2_rst <- terra::mask(W2_rst, borders)
terra::plot(W2_rst, main="Latent variable W2 interpolated by RST")
W2_rst_xy <- terra::extract(W2_rst, xy)[, "W2_rst"]
plot(W2_rst_xy, params_sites$W2,
xlab="W2 interpolated by RST",
ylab="W2 estimated by JSDM",
main="Second latent axis")
abline(a=0, b=1, col='red')
# Center interpolated first latent axis
W2_rst_centered <- terra::app(W2_rst, scale, scale=FALSE)
names(W2_rst_centered) <- names(W2_rst)
terra::plot(W2_rst_centered, main="Second latent axis interpolated by RST")
W2_rst_centered_xy <- terra::extract(W2_rst_centered, xy)[,"W2_rst"]
plot(W2_rst_centered_xy, params_sites$W2,
xlab="W2 interpolated by RST",
ylab="W2 estimated by JSDM",
main="Second latent axis")
abline(a=0, b=1, col='red')
terra::writeRaster(W2_rst_centered, "Madagascar_cache/W2_rst_centered.tif",
gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)We represent the second latent variable interpolated at Madagascar scale.
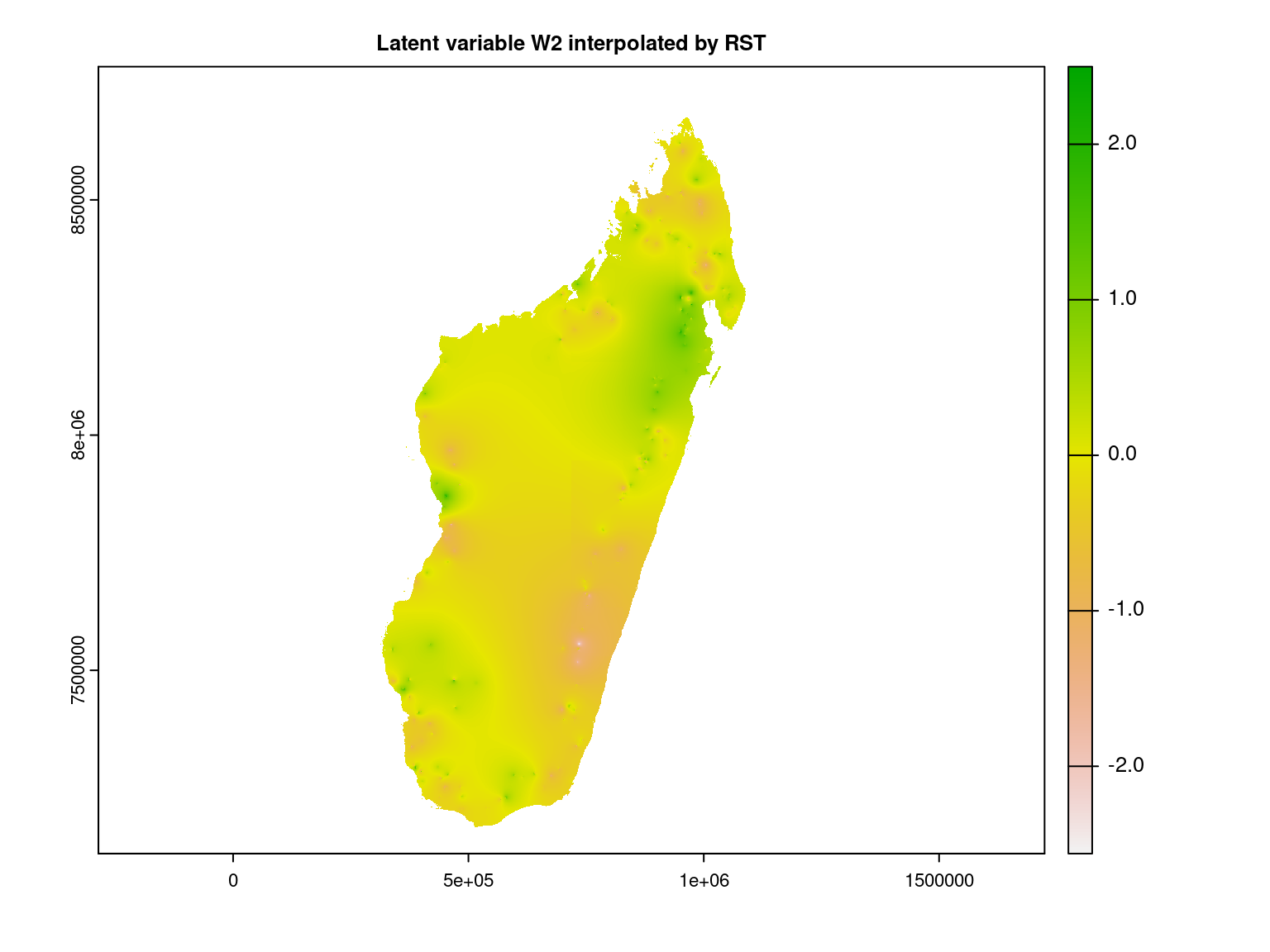
6 Representation of results at the Madagascar scale
6.1 Predictives maps of presence probabilities
We calculate the probabilities of species presences between inventory sites using interpolated site’s parameters.
remove(list = ls())
# RST interpolation of sites parameters
rst_alpha <- terra::rast("~/Documents/jSDM/vignettes/Madagascar_cache/alpha_rst_centered.tif")
rst_W1 <- terra::rast("~/Documents/jSDM/vignettes/Madagascar_cache/W1_rst_centered.tif")
rst_W2 <- terra::rast("~/Documents/jSDM/vignettes/Madagascar_cache/W2_rst_centered.tif")
# Species parameters
params_species <- read.csv(file = "~/Documents/projet_BioSceneMada/Internship_Report/data/params_species.csv")
nsp <- nrow(params_species)
# Current climatic variables
X <- read.csv(file = "~/Documents/projet_BioSceneMada/Internship_Report/data/X.csv")
scaled_clim_var <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/scaled_clim.tif")
names(scaled_clim_var) <- colnames(X[,-1])
terra::ext(scaled_clim_var) <- terra::ext(rst_alpha)
if(terra::crs(scaled_clim_var) != terra::crs(rst_alpha)){
scaled_clim_var <- terra::project(scaled_clim_var, terra::crs(rst_alpha))
}
# Function to compute probit_theta at Madagascar scale
predfun <- function(scaled_clim_var, params_species, rst_alpha, rst_W1, rst_W2, species.range){
lambda_1 <- as.matrix(params_species[,"lambda_1"])
lambda_2 <- as.matrix( params_species[,"lambda_2"])
beta <- as.matrix(params_species[,3:13])
## Xbeta_1
np <- terra::nlyr(scaled_clim_var)
Xbeta_1 <- terra::rast(ncols=dim(rst_alpha)[2], nrows=dim(rst_alpha)[1],
ext=terra::ext(rst_alpha), crs=terra::crs(rst_alpha),
resolution=terra::res(rst_alpha))
terra::values(Xbeta_1) <- rep(beta[1,1][[1]], terra::ncell(Xbeta_1))
for (p in 1:np) {
Xbeta_1 <- Xbeta_1 + scaled_clim_var[[p]]*beta[1,p+1]
}
## Wlambda_1
Wlambda_1 <- rst_W1*lambda_1[1] + rst_W2*lambda_2[1]
## probit_theta_1
probit_theta_1 <- Xbeta_1 + Wlambda_1 + rst_alpha
probit_theta <- probit_theta_1
remove(list=c("probit_theta_1","Wlambda_1"))
## Other species
for (j in (species.range[1]+1):species.range[2]) {
## Xbeta_j
Xbeta_j <- Xbeta_1
terra::values(Xbeta_j) <- rep(beta[j,1][[1]], terra::ncell(Xbeta_j))
for (p in 1:np) {
Xbeta_j <- Xbeta_j + scaled_clim_var[[p]]*beta[j,p+1]
}
## Wlambda_j
Wlambda_j <- rst_W1*lambda_1[j] + rst_W2*lambda_2[j]
## probit_theta_j
probit_theta_j <- Xbeta_j + Wlambda_j + rst_alpha
probit_theta <- c(probit_theta, probit_theta_j)
remove(list=c("probit_theta_j", "Xbeta_j", "Wlambda_j"))
}
names(probit_theta) <- make.names(params_species$species[species.range[1]:species.range[2]])
return(probit_theta)
}
# Compute theta in ten parts because it's too large
npart <- 10
first.species <- seq(1, nsp, by=floor(nsp/npart)+1)
for (n in 1:npart){
probit_theta <- predfun(scaled_clim_var, params_species,
rst_alpha, rst_W1, rst_W2,
species.range=c(first.species[n],
min(nsp,first.species[n]+floor(nsp/npart))))
terra::writeRaster(probit_theta,
filename=paste0("~/Documents/projet_BioSceneMada/Internship_Report/data/RST_probit_theta_", n, ".tif"),
filetype="GTiff",
gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)
# Compute and save SpatRaster of probabilities of presence theta
terra::app(probit_theta, pnorm, cores=2,
filename=paste0("~/Documents/projet_BioSceneMada/Internship_Report/data/RST_theta_",n,".tif"), overwrite=TRUE, wopt=list(gdal=c("COMPRESS=LZW", "PREDICTOR=2"), filetype="GTiff"))
remove(probit_theta)
}We represent the presence probabilities of two species interpolated at the scale of Madagascar as well as their observed occurrences at the inventory sites represented by black crosses.
params_species <- read.csv(file = "~/Documents/projet_BioSceneMada/Internship_Report/data/params_species.csv")
nsp <- nrow(params_species)
xy <- terra::vect("/home/clement/Documents/projet_BioSceneMada/Internship_Report/data/coords.shp")
data(madagascar, package="jSDM")
PA <- madagascar
# Observed presence absence
id_pres_Ocotea <- which(PA[,"sp_1"]==1)
obs_pres_Ocotea <- terra::vect(terra::crds(xy[id_pres_Ocotea,]),
type="point", crs=terra::crs(xy))
id_pres_Manilkara <- which(PA[,"sp_6"]==1)
obs_pres_Manilkara <- terra::vect(terra::crds(xy[id_pres_Manilkara,]),
type="point", crs=terra::crs(xy))
# Representation
npart <- 10
first.species <- seq(1,nsp,by=floor(nsp/npart)+1)
theta <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/RST_theta_1.tif")
names(theta) <- paste0("sp_", first.species[1]:(first.species[1]+floor(nsp/npart)))
par(mfrow=c(1,2), oma=c(1, 0, 2, 1), mar=c(5, 4, 3, 2))
terra::plot(theta$sp_1,
main="Ocotea.laevis")
terra::points(obs_pres_Ocotea, pch=3, cex=0.7)
terra::plot(theta$sp_6,
main="Manilkara.hexandra")
terra::points(obs_pres_Manilkara, pch=3, cex=0.7)
title(main="Interpolated current probabilities of presence",
outer=T, cex.main=1.3)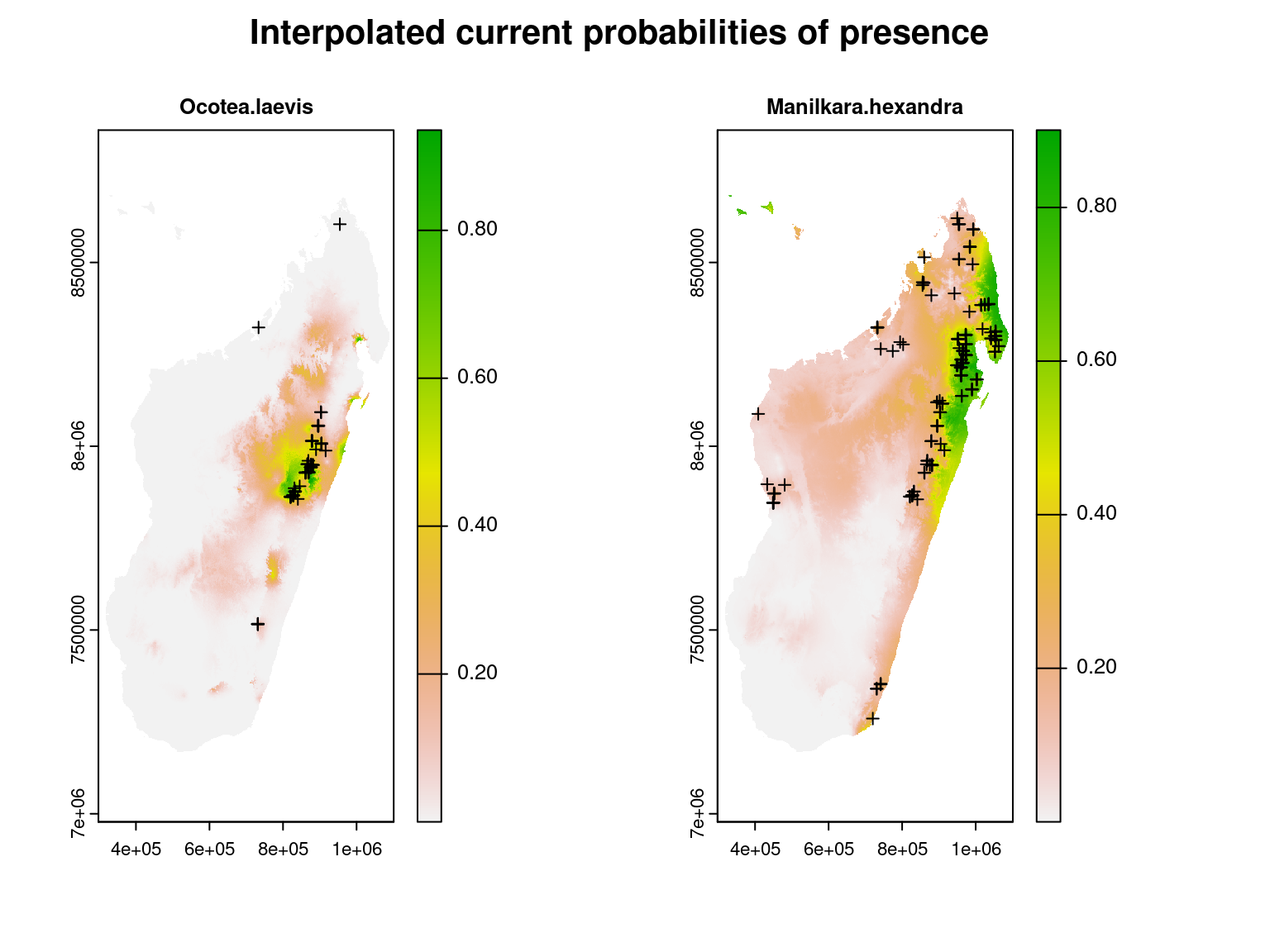
We can see that the areas with high estimated probabilities of occurrence for these species correspond well to the inventory sites where these species have been observed.
6.2 Predictive maps of species richness (diversity \(\alpha\))
Species richness also called diversity \(\alpha\) reflects the number of species coexisting in a given environment and is computed by summing the number of species present on each site.
6.2.1 Current species richness
We compute at Madagascar scale the species richness by summing the interpolated probabilities of occurrence for each map’s cell \(i\) : \(\widehat{R}_i=\sum\limits_ {j=1}^{n_{species}} \widehat{\theta}_{ij}\).
theta <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/RST_theta_1.tif")
species_richness <- terra::app(theta, sum)
npart <- 10
for(n in 2:npart){
theta <- terra::rast(paste0("~/Documents/projet_BioSceneMada/Internship_Report/data/RST_theta_",
n, ".tif"))
species_richness <- species_richness + terra::app(theta, sum)
}
names(species_richness) <- "species_richness"
terra::writeRaster(species_richness,
filename=paste0("~/Documents/projet_BioSceneMada/Internship_Report/data/species_richness.tif"),
filetype="GTiff", gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)6.2.2 Current species richness restricted to forest cover
However, the model used does not take into account human presence, which is manifested in particular by the deforestation of the island, so we use data on remaining forest cover in 2000 from the article Vieilledent et al. (2018) in order to replace with zero values the interpolated species richness at locations where forest is known to have been removed.
library(glue)
# raster of Madagascar's forest cover in 2000
forest <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/for2000.tif")
# change resolution of species richness raster from 1000x1000m to 30x30m
in_f <- "~/Documents/projet_BioSceneMada/Internship_Report/data/species_richness.tif"
out_f <- "~/Documents/projet_BioSceneMada/Internship_Report/data/species_richness_30m.tif"
cmd <- glue('gdalwarp -tr 30 30 -te {xmin(forest)} {ymin(forest)} {xmax(forest)} {ymax(forest)} -r near -co "COMPRESS=LZW" -co "PREDICTOR=2" -overwrite {in_f} {out_f}')
system(cmd)
# remove species richness values where there was no forest in 2000s
species_richness <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/species_richness_30m.tif")
species_richness_deforest <- terra::mask(species_richness, forest)
terra::writeRaster(species_richness_deforest,
filename="~/Documents/projet_BioSceneMada/Internship_Report/data/species_richness_deforest.tif",
filetype="GTiff", gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)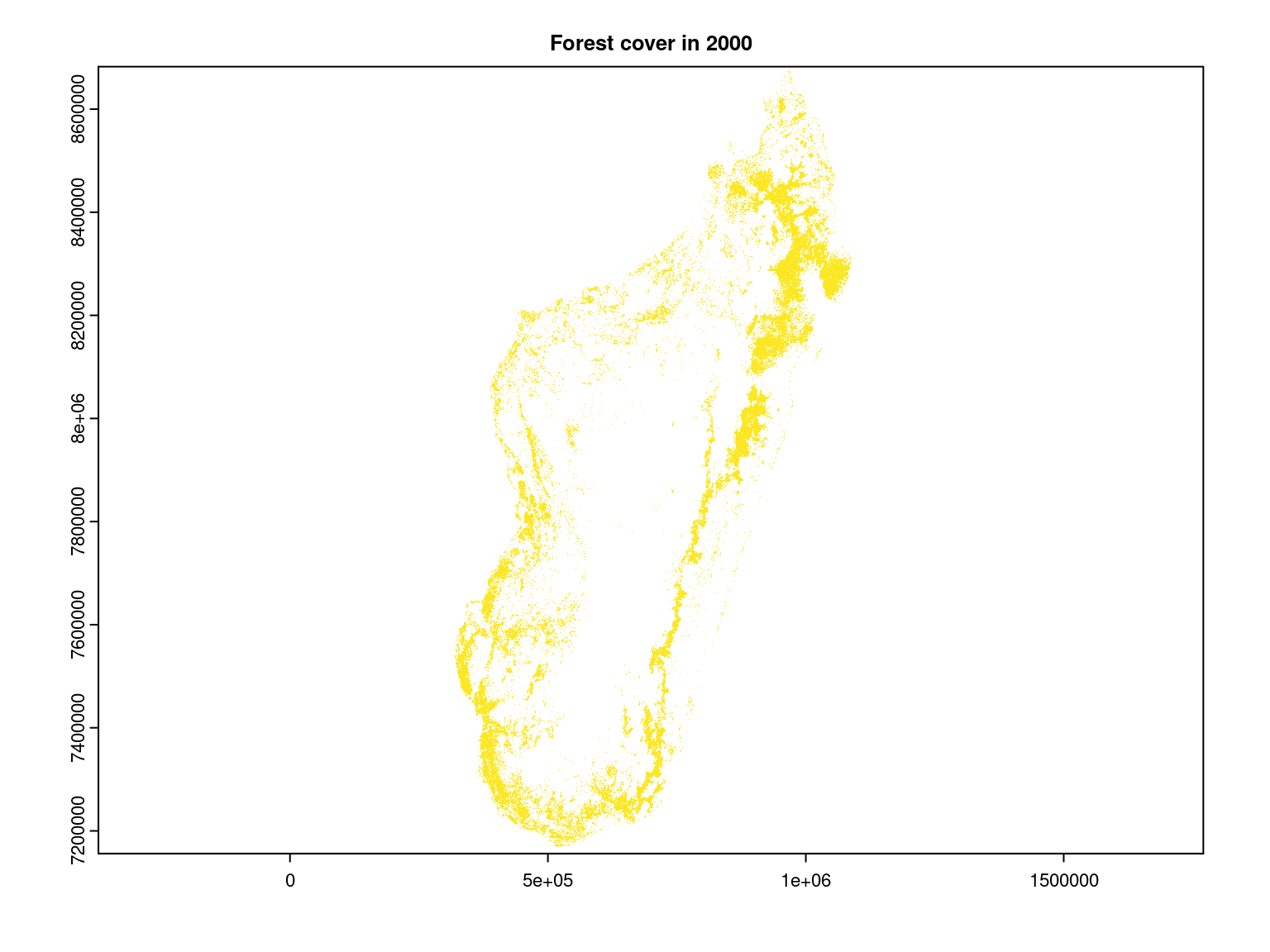
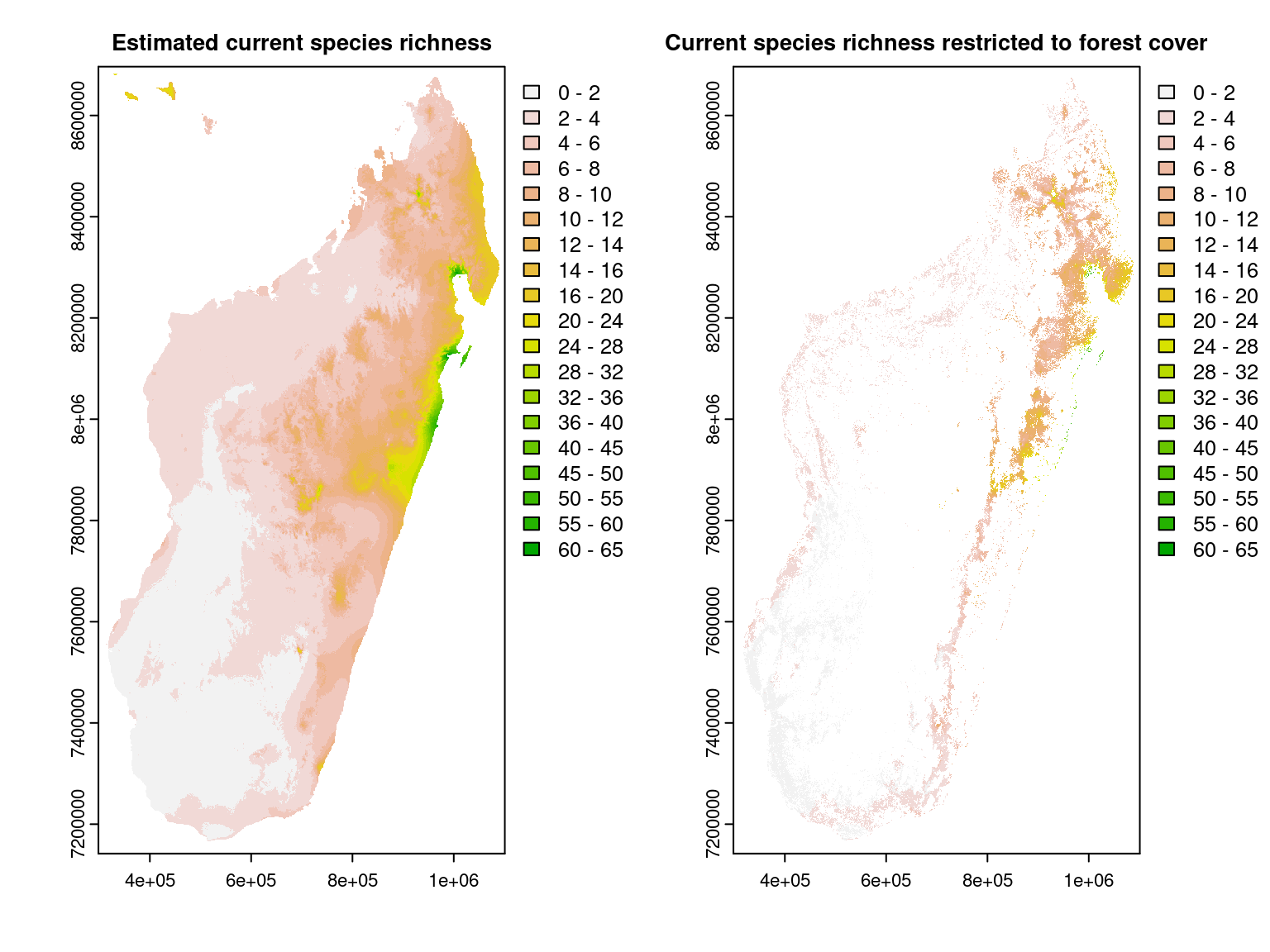
We can see that the species richness, computed from interpolated occurrence probabilities, is greater in the moist forest of the north-east of the island, particularly in the Masoala peninsula as expected given the observed species richness on inventory sites.
It can be explained by the fact that this area is located close to the
Equator and is receiving the highest level of precipitation in
Madagascar. As a consequence, this area benefits from high levels of
resources (light and water) and is characterized by a low environmental
stress and a long growing season (Vieilledent et al. 2013).
Note that the estimated species richness does not necessarily stand for a ‘true’ number of present species but represent a relative species richness between sites (one site is richer in species than another site).
6.3 Predictive maps of species turnover (diversity \(\beta\))
Diversity \(\beta\) is a measure of biodiversity that compares the diversity of species between ecosystems or along environmental gradients, using the number of taxa that are unique to each ecosystem.
In order to estimate this indicator, we proceed in the same way as in the article Allnutt et al. (2008) by performing a standard PCA on the interpolated probabilities of occurrence of species for each pixel of the displayed image. We use the coordinates obtained for the first three axes of the PCA that reflect the composition of the species community likely to occupy the corresponding pixel. These coordinates are scaled \([0.255]\) so that they can be represented by red color levels for the first axis, green for the second and blue for the third. The combination of these three color levels determines the coloring of each pixel in the displayed \(\beta\) diversity map. Therefore, a color difference between two pixels indicates that the species present are not the same, while pixels of identical color host communities of similar species.
6.3.1 Current species turn-over
# Sample 10000 cells of presence probabilities raster
npart <- 10
theta <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/RST_theta_1.tif")
samp_theta <- terra::spatSample(theta, size=10000, method="random",
ext=terra::ext(theta), na.rm=TRUE, cells=TRUE)
samp_cells <- samp_theta[,"cell"]
samp_theta <- samp_theta[,-1]
for(n in 2:npart){
theta <- terra::rast(paste0("~/Documents/projet_BioSceneMada/Internship_Report/data/RST_theta_", n, ".tif"))
samp_theta <- cbind(samp_theta, theta[samp_cells])
}
params_species <- read.csv(file = "~/Documents/projet_BioSceneMada/Internship_Report/data/params_species.csv")
colnames(samp_theta) <- params_species$species
# Data frame to compute PCA on pixels dissimilarity
theta_df <- data.frame(samp_theta)
pca_theta <- ade4::dudi.pca(theta_df, center=TRUE, scale=TRUE, nf=3, scannf = FALSE)
save(pca_theta, samp_cells, file="~/Documents/projet_BioSceneMada/Internship_Report/data/PCA_theta.RData")
str(pca_theta)
# Perform projections of PCA results on all raster's rows in parallel
# Coordinates on the 3 axes retained in the PCA
coords <- theta[[c(1,2,3)]]
terra::values(coords) <- 0
names(coords) <- colnames(pca_theta$li)
for(k in 1:nrow(theta)){
cat(k, "/", nrow(theta),"\n")
theta <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/RST_theta_1.tif")
## Make a cluster for parallel computation
# detect the number of CPU cores on the current host
ncores <- parallel::detectCores()
clust <- makeCluster(ncores)
registerDoParallel(clust)
theta_k <- foreach(n=1:npart, .combine = "cbind") %dopar%{
theta <- terra::rast(paste0("~/Documents/projet_BioSceneMada/Internship_Report/data/RST_theta_",
n, ".tif"))
theta_k <- terra::values(theta, row=k, nrows=1)
return(theta_k)
}
stopCluster(clust)
colnames(theta_k) <- params_species$species
theta_k <- data.frame(theta_k)
coords[k,] <- as.matrix(ade4::suprow(pca_theta,theta_k)$lisup)
}
terra::writeRaster(coords,
filename="~/Documents/projet_BioSceneMada/Internship_Report/data/coords.tif",
filetype="GTiff", gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)
# Change the coordinate scale for [0.255].
## Min reduced to 0
Min <- terra::minmax(coords)["min",]
Min
coords_RGB <- coords
for (l in 1:3) {
coords_RGB[[l]] <- coords[[l]] - Min[l]
}
Min2 <- terra::minmax(coords_RGB)["min",]
Min2
## Max at 255
remove(coords)
Max <- terra::minmax(coords_RGB)["max",]
Max
for (l in 1:3) {
coords_RGB[[l]] <- (coords_RGB[[l]] / Max[l])*255
}
Max2 <- terra::minmax(coords_RGB)["max",]
Max2
# Coloration RGB
terra::writeRaster(coords_RGB,
filename=paste0("~/Documents/projet_BioSceneMada/Internship_Report/data/species_turnover.tif"),
filetype="GTiff", gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)6.3.2 Current species turn over restricted to forest cover
In the same way as above, we restrict the values obtained for diversity \(\beta\) to the forest cover remaining in 2000.
library(glue)
# raster of Madagascar's forest cover in 2000
forest <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/for2000.tif")
# current species turnover
# change resolution of species richness raster from 1000x1000m to 30x30m
in_f <- "~/Documents/projet_BioSceneMada/Internship_Report/data/species_turnover.tif"
out_f <- "~/Documents/projet_BioSceneMada/Internship_Report/data/species_turnover_30m.tif"
cmd <- glue('gdalwarp -tr 30 30 -te {xmin(forest)} {ymin(forest)} {xmax(forest)} {ymax(forest)} -r near -co "COMPRESS=LZW" -co "PREDICTOR=2" -overwrite {in_f} {out_f}')
system(cmd)
# remove species richness values where there was no forest in 2000s
species_turnover <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/species_turnover_30m.tif")
species_turnover_deforest <- terra::mask(species_turnover,forest)
terra::writeRaster(species_turnover_deforest,
filename="~/Documents/projet_BioSceneMada/Internship_Report/data/species_turnover_deforest.tif",
filetype="GTiff", gdal=c("COMPRESS=LZW", "PREDICTOR=2"), overwrite=TRUE)
# Representation of species turn over restricted to forest cover in 2000's
species_turnover_current <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/species_turnover_30m.tif")
species_turnover_deforest <- terra::rast("~/Documents/projet_BioSceneMada/Internship_Report/data/species_turnover_deforest.tif")
par(mfrow=c(1,2))
terra::plotRGB(species_turnover_current, stretch="hist",
mar=c(1,1,1,1),
main="Estimated current species turn over")
terra::plotRGB(species_turnover_deforest, stretch="hist",
mar=c(1,1,1,1),
main="Current species turn over on forest cover")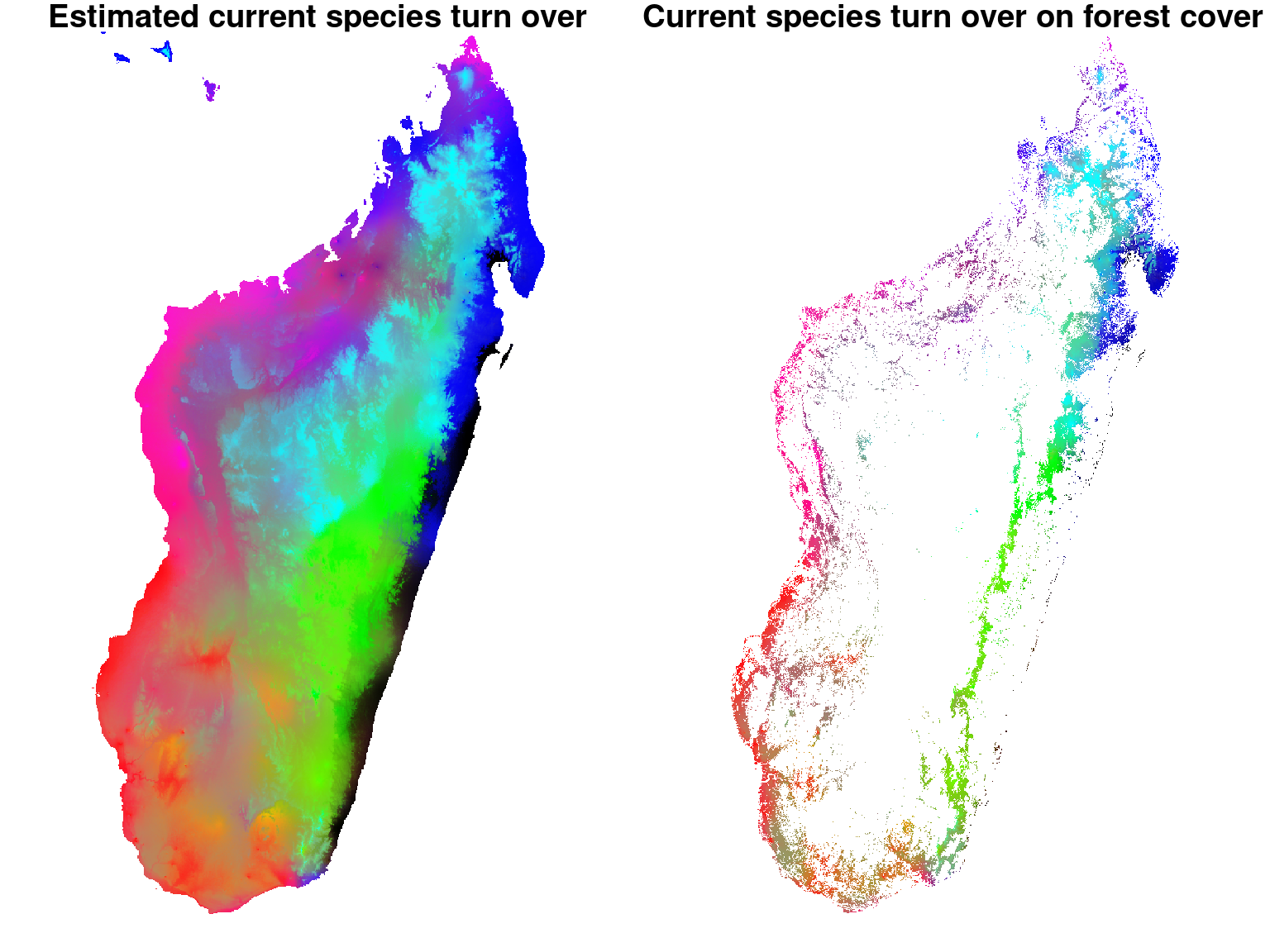
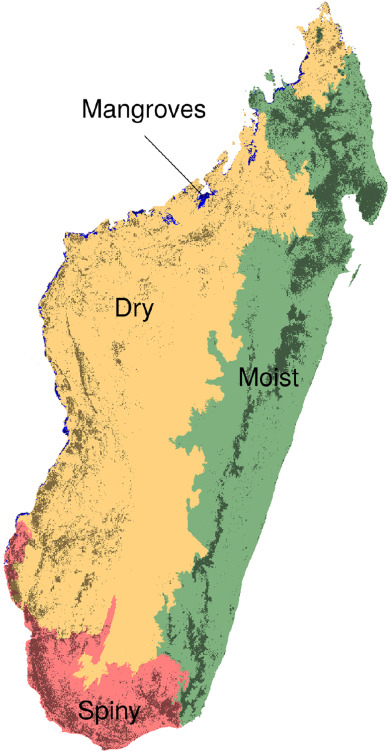
Figure 6.1: Forest types in Madagascar (Vieilledent et al. 2018).
We can see that the estimated map of \(\beta\)-diversity agrees with the map of Madagascar’s forest types from the article Vieilledent et al. (2018).
Indeed, communities of species represented by shades of blue and green correspond to the eastern moist forest, communities represented by shades of red match the western dry forest and communities in magenta correspond to the southern spiny forest.
Moreover, the \(\beta\)-diversity map we obtain allows to identify substantially different species communities within these three forest types. For example, we can clearly identify three different tree communities (in blue, green, and black) within the eastern moist forest.